Multi-Modal AI is rapidly taking over.
It’s truly amazing how fast LlamaIndex incorporated a robust pipeline for multi-modal RAG capabilities.
Here’s a beginners-friendly guide to get started with multi-modal RAG using LlamaIndex.
Multi-Modal LLM
First let’s start with some simple stuff.
We just want to ask questions about our images.
OpenAIMultiModal is a wrapper around OpenAI’s latest vision model that lets us do exactly that.
- First we create documents as usual, like below:
image_documents = SimpleDirectoryReader("./input_images").load_data()
- Next we initialize the multi-modal llm instance:
openai_mm_llm = OpenAIMultiModal()
- Then, we pass the image_documents to the
complete()method of thellm.Usestream_complete()instead ofcomplete()for token streaming.
response = openai_mm_llm.complete(
prompt="Describe the images as an alternative text",
image_documents=image_documents,
)
print(response)

We can see it that the multi-modal llm responded with an alternative text for each of the input images.
Told you it was easy. LlamaIndex handles all the underlying logic for converting those image_documents to compatible format for the multi-modal llm.
But there’s an issue !!
Just like text based RAG, where we were limited by the context length, here we’re also limited by how many images we pass.
We can’t just pass loads of images. We would only want to pass those images that are related to our query.
How do you find images related to your query?? Yep, with the help of EMBEDDING
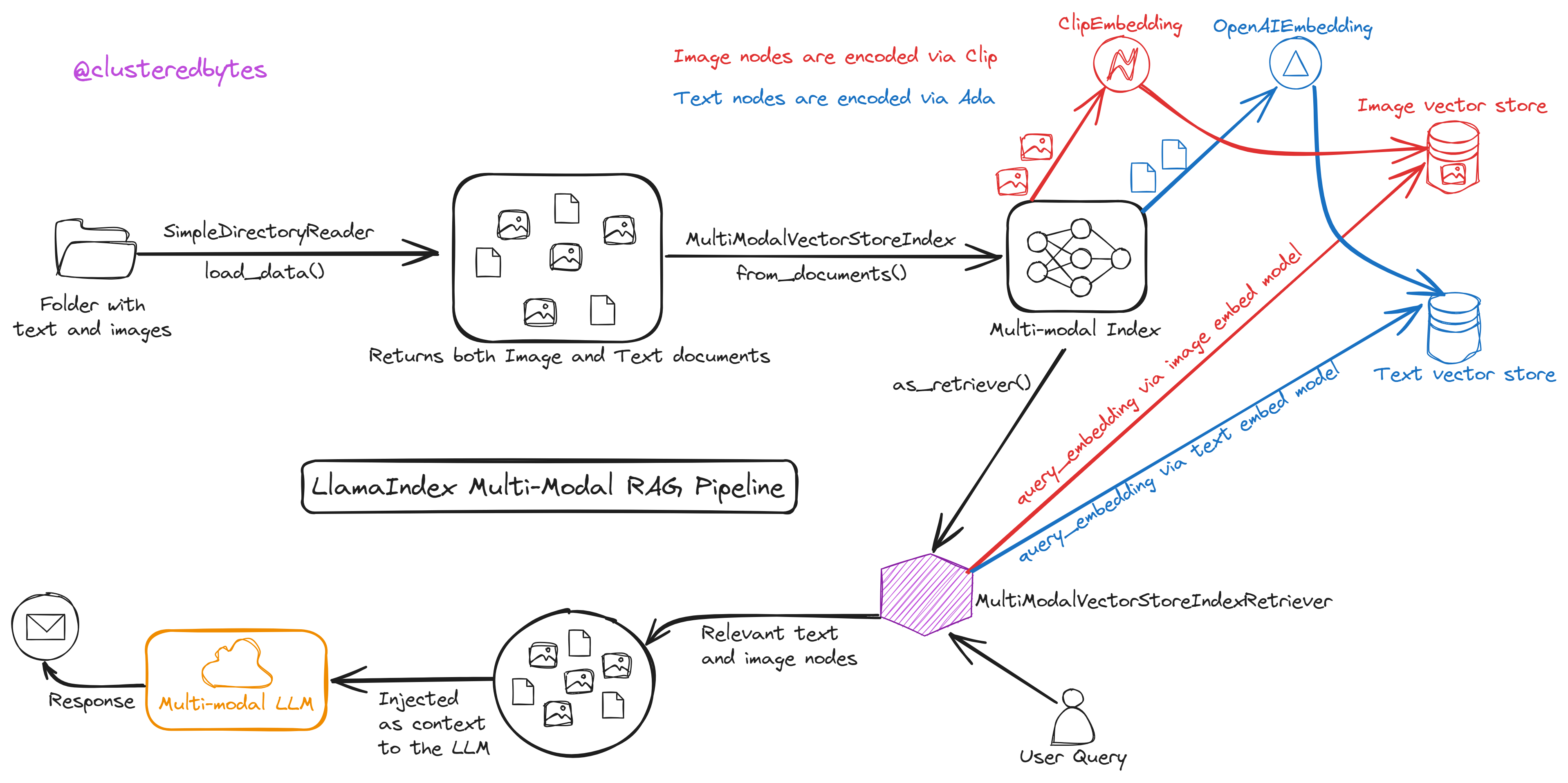
Multi-Modal Vector Store Index
LlamaIndex has MultiModalVectorStoreIndex which creates embedding for both image and text nodes and stores them in vector stores.
For image nodes it uses clip and for text nodes it uses ada for getting the embedding.
Let’s create the multi-modal index
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()
index = MultiModalVectorStoreIndex.from_documents(documents)
Here we pass the loaded documents, which could include both image and text nodes.
In this function we can specify the vector stores to use for text and image. By default, it uses simple in-memory vector stores.
Here’s how to use two different Qdrant vector stores for image and text nodes:
# Create a local Qdrant vector store
client = qdrant_client.QdrantClient(path="qdrant_mm_db")
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()
index = MultiModalVectorStoreIndex.from_documents(
documents, storage_context=storage_context, image_vector_store=image_store
)
Now that we’ve created the multi-modal index, we wanna retrieve relevant nodes(both image and text) from that index, based on our query.
Multi-Modal Vector Store Index Retriever
So we create a MultiModalVectorIndexRetriever from the index:
mm_retriever = index.as_retriever()
retrieval_results = mm_retriever.retrieve('here goes my query')
We can specify how many relevant text and image nodes to retrieve by passing similarity_top_k=3, image_similarity_top_k=3 while creating the retriever.
While encoding the queries, the above retriever encodes query text using both the embed_model and image_embed_model
Thus, the query_embedding from the embed_model is used to retrieve text nodes from the text vector store.
And the query_embedding from the image_embed_model is used to retrieve image nodes from the image vector store.
Multi-Modal Query Engine
Now that we have retrieved the relevant image and text nodes using the multi-modal retriever above, let’s create a multi-modal query engine so that we can query about the retrieved image and text nodes.
query_engine = index.as_query_engine()
query_str = "Tell me more about the Porsche"
Here we create the query engine from the as_query_engine() method of the index which first creates the retriever like we did earlier, and then creates the query engine from that retriever.
We can pass the multi_modal_llm and text_qa_template if we don’t wanna use the default one:
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm, text_qa_template=qa_tmpl
)
The query engine then passes the retrieved text and image nodes as context to the Vision API.
Now let’s use the query engine:
query_str = "Tell me more about the Porsche"
response = query_engine.query(query_str)
print(str(response))
The multi-modal query engine stores the retrieved image and text nodes by the multi-modal retriever in the metadata of the response.
If we inspect those nodes from the metadata, we can see that 3 text nodes and 2 images were retrieved for the given query.

These were all sent to the multi-modal llm as context to get the final response.
Here’s the official documentation for LlamaIndex multi-modal retrieval
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter