Previously we’ve seen how to improve retrieval by finetuning an embedding model.
LlamaIndex also supports finetuning an adapter on top of existing models, which lets us improve retrieval without updating our existing embeddings. 🚀
It also allows us to use any black-box embedding model we want to use.
Let’s see how it works 👇
Adapters
For finetuning the model, we pull apart every single layer of the transformer, add randomly initialized new weights.
For adapters, we pull apart every single layer of the transformer and add randomly initialized new weights.
Then, instead of finetuning all the weights, we freeze the weights of the pre-trained model, only finetune the newly added weights.
We apply similar technique here.
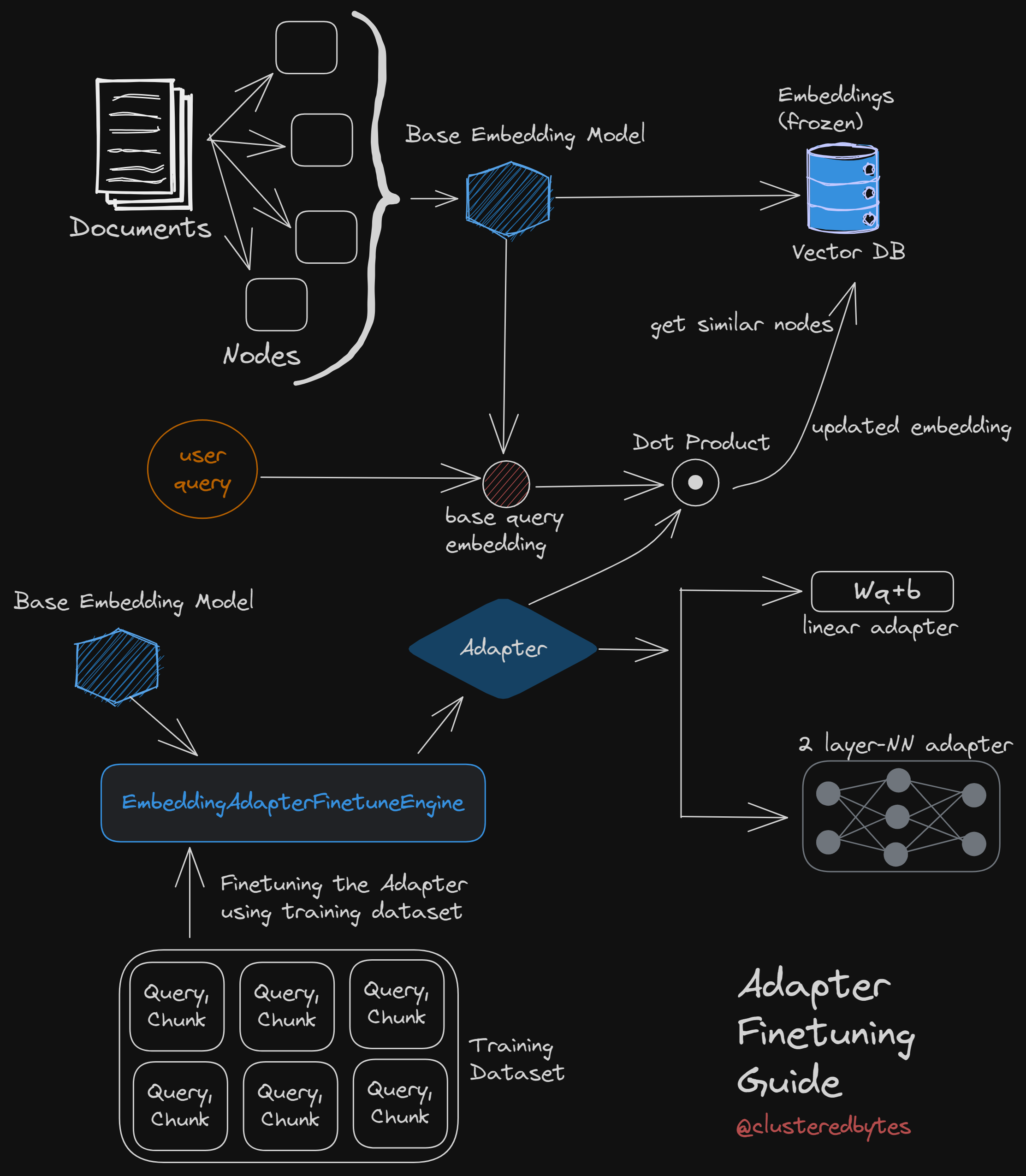
Embedding adapters
Here we “freeze” the document embeddings, and then we train a transformation on the query embedding instead.
Thus we’re not limited to only Sentence Transformer models.
We can apply this on top of any existing model without re-embedding existing data.
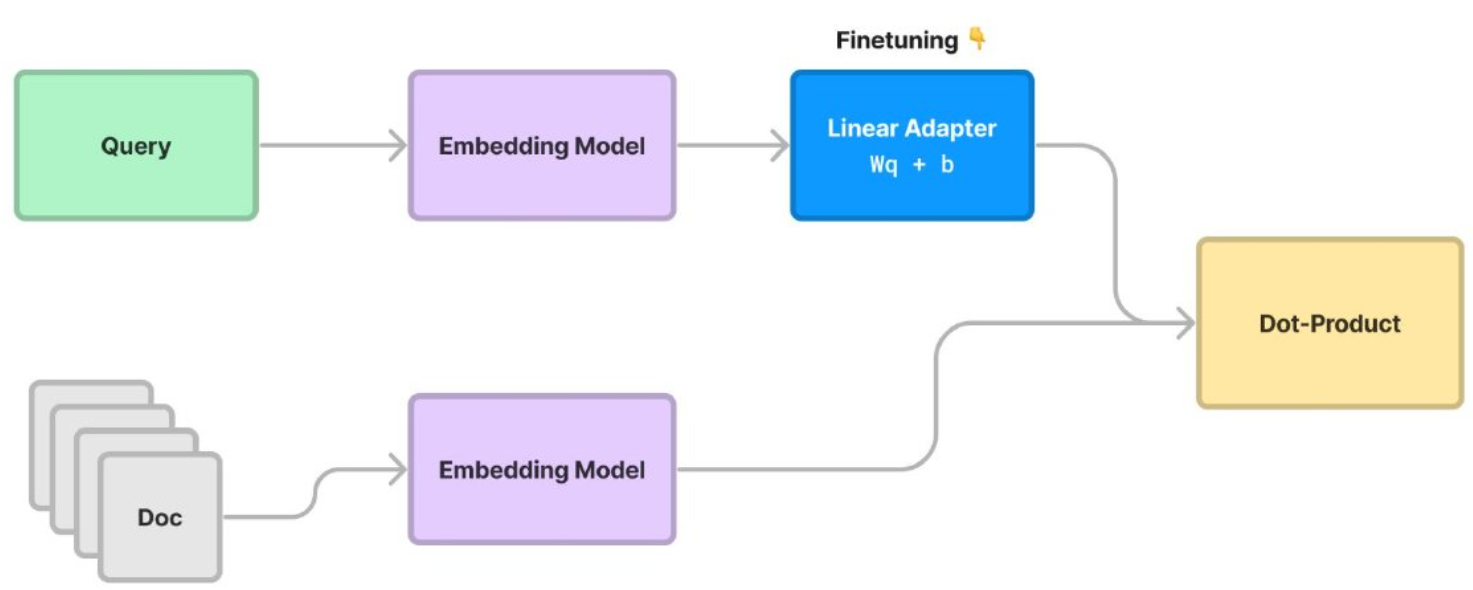
Linear Adapter
The query embedding is updated using this linear transformation of the adapter:
updated_q = W*q + b
We train the linear adapter on the training corpus to find the best value for the weight and bias, W and b.
Steps for finetuning adapters
3 steps for finetuning adapters:
- generate set of synthetic query-context pairs from training and evaluation dataset.
- Fine-tuning our linear adapter on top of an existing model (e.g. ada)
- Get the updated model using the base model and the adapter.
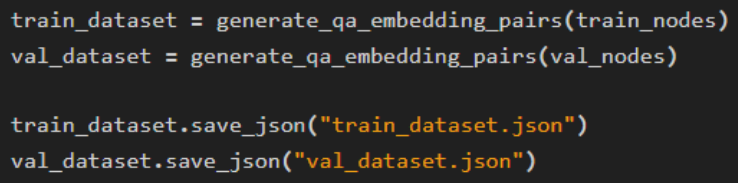
Generate dataset
we use the generate_qa_embedding_pairs() function from LlamaIndex to generate both training and evaluation datasets.
Finetune
Now, we create the finetune engine with all the parameters.
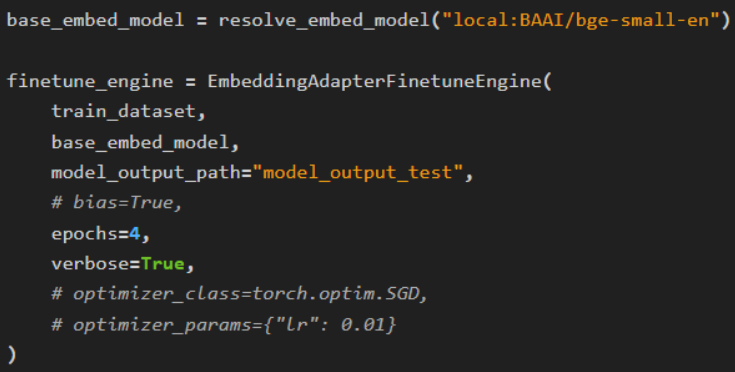
Next we perform finetuning using engine.finetune()
Finetuning adapter is not resource hungry and can be done on a macbook, no beefy GPU required.
Then, we get the model with finetuned adapter using engine.get_finetuned_model()
We can also get the model with the finetuned adapter from the base model and the model path of the trained adapter:

After getting the model, we use it as usual.
Multi-layer NN Adapters
Instead of simple linear adapter, LlamaIndex also supports Advanced transformation using Deeper Neural Networks e.g. TwoLayerNN or even our own custom model by subclassing the BaseAdapter class.
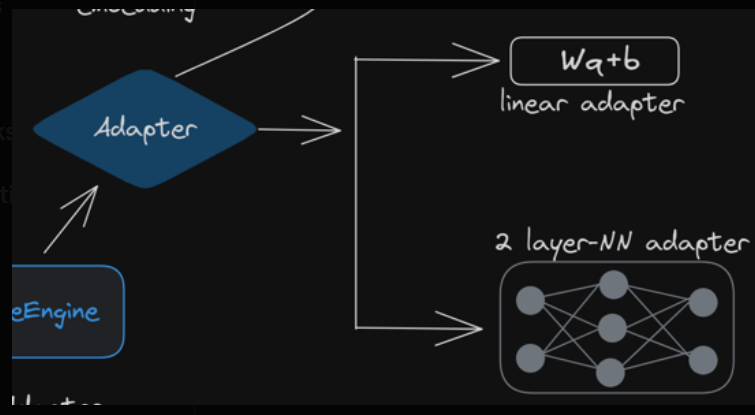
Two Layer Adapter
LlamaIndex has a TwoLayerNN abstraction to easily create a simple two-layer Neural network with a ReLU activation and a residual layer at the end as the adapter.
We define the two layer model with its dimensions
base_embed_model = resolve_embed_model("local:BAAI/bge-small-en")
adapter_model = TwoLayerNN(
384, # input dimension
1024, # hidden dimension
384, # output dimension
bias=True,
add_residual=True,
)
Next, while creating the finetune engine, we pass this adapter_model as argument
finetune_engine = EmbeddingAdapterFinetuneEngine(
train_dataset,
base_embed_model,
model_output_path="model5_output_test",
model_checkpoint_path="model5_ck",
adapter_model=adapter_model,
epochs=25,
verbose=True,
)
Custom Model
We can define our own adapter model by inheriting from the BaseAdapter class.
This class is a light wrapper around nn.Module
Checkout the docs here to see how to define custom adapter models.
Conclusion
As document embeddings are unchanged, we can choose to arbitrarily re-train this adapter in the future on top of changing data distributions.
Though performance increase is not as good as finetuning the entire model, but still slightly better than the pre-trained model.
Full guide with benchmarks in the official documentation here
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter