Ingestion Pipeline is a new and improved way to ingest and manage documents in LlamaIndex.
It’s really useful if our RAG pipeline requires input documents to go through a sequential list of transformation(chunking, embedding etc.) before creating index.
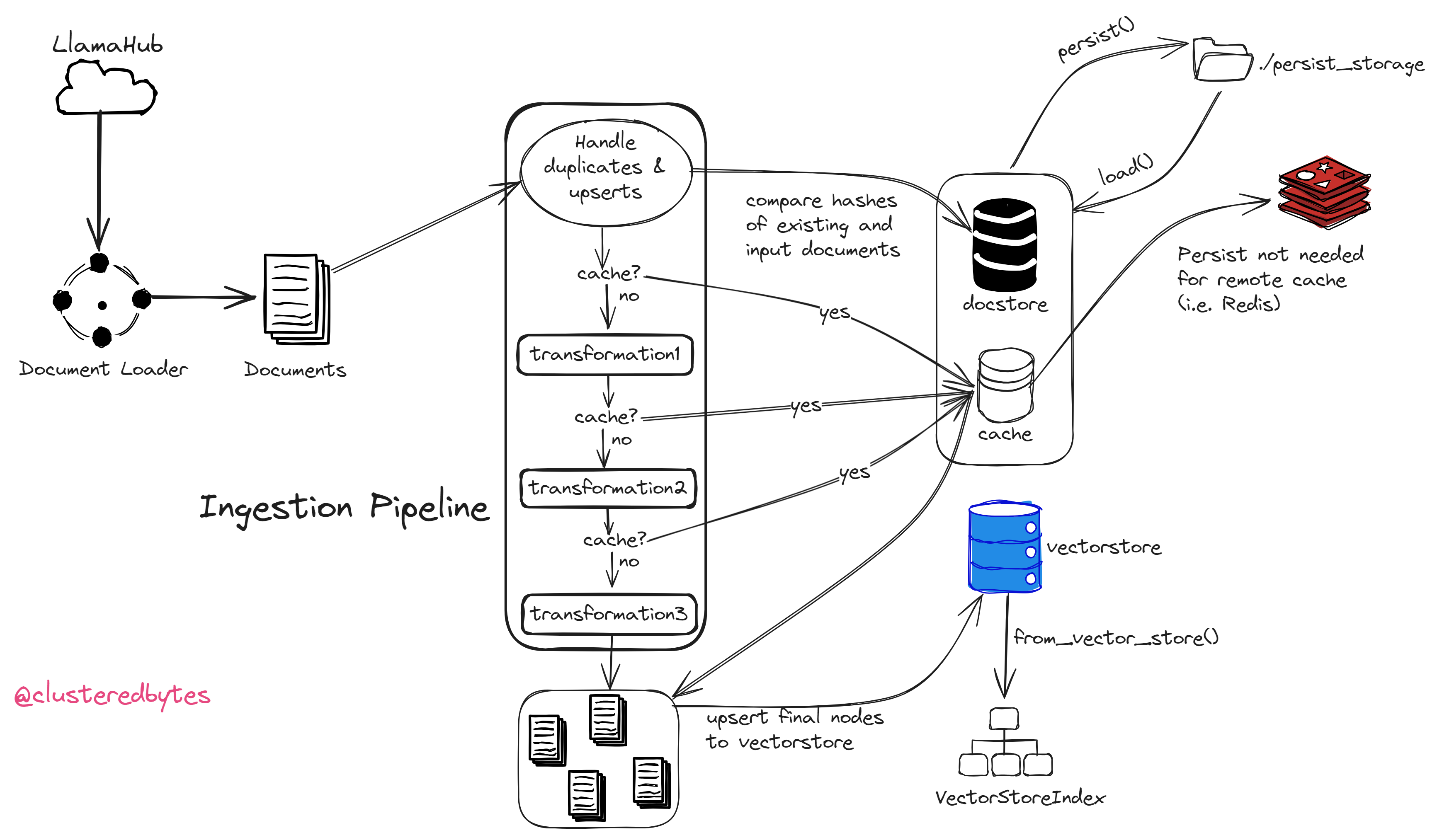
It also has useful features like caching, docstore management, vectorstore upserting etc.
Transformation
Transformations are the building blocks of Ingestion Pipeline.
Each transformation takes a list of nodes, and returns another list of nodes after making the desired modifications to them. Ingestion pipeline consists of a sequential list of these transformations.
We define the transformations while instantiating the pipeline itself.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
]
)
These are the transformations we can use:
- TextSplitter
- NodeParser
- MetadataExtractor
- Any embedding model
We can also create custom transformations. Guide on this is coming soon.
Caching
When we run the pipeline, the output from one transformation is passed to the next one as input.
The input nodes list and the transformation pair is cached in the pipeline. So if we try to perform the same transformation on that same list of nodes again, the output nodes will be fetched from the cache.
we can clear the cache by ingest_cache.clear()
We can also use other services like Redis for caching like this:
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
],
cache=IngestionCache(
cache=RedisCache(
redis_uri="redis://127.0.0.1:6379", collection="test_cache"
)
),
)
Document management
To make sure that we don’t run a transformation on same document multiple times, Ingestion pipeline uses the document id and the hash of the document content to handle duplicates.
To enable document management, we need to pass a docstore to the pipeline.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
],
docstore=SimpleDocumentStore()
)
The hashes of the existing documents in the docstore will be compared to the hashes of the input documents and the unchanged documents will be excluded from transformation.
There are 3 strategies for document management.
- Checks for duplicates only
- Handle upserting
- Handle upserting and deletes old documents.
Guide on them coming soon.
Add to vectorstore
If we pass a vectorstore to the pipeline, then it will automatically add the final output nodes from the transformation sequence to that vectorstore.
import qdrant_client
client = qdrant_client.QdrantClient(location=":memory:")
vector_store = QdrantVectorStore(client=client, collection_name="test_store")
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
],
vector_store=vector_store,
)
# Ingest directly into a vector db
pipeline.run(documents=[Document.example()])
we can then use that populated vectorstore to create a vectorstore index.
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_vector_store(vector_store)
For this, the last transformation in the sequence must be an embedding transformation.
Persisting
Ingestion pipeline allows persisting the cache and the docstore to a folder (./pipeline_storage by default)
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# Now let's save the pipeline (cache and docstore)
pipeline.persist('./pipeline_storage')
after defining the pipeline, we need to load it from the storage like this:
pipeline.load('./pipeline_storage')
Now if we run the pipeline, it’ll reuse the cache before persisting, and also it’ll skip the same documents from the docstore.
Note that if we use remote cache/docstore i.e. Redis, then the above persisting step is not needed.
Conclusion
Thus, the new Ingestion Pipeline by LlamaIndex makes it really efficient and intuitive to ingest and manage documents and apply a sequence of transformation on them.
Check out the official documentation: Ingestion Pipeline
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter