Finetuning the embedding model can allow for more meaningful embedding representations, leading to better retrieval performance.
LlamaIndex has abstraction for finetuning sentence transformers embedding models that makes this process quite seamless.
Let’s see how it works 👇
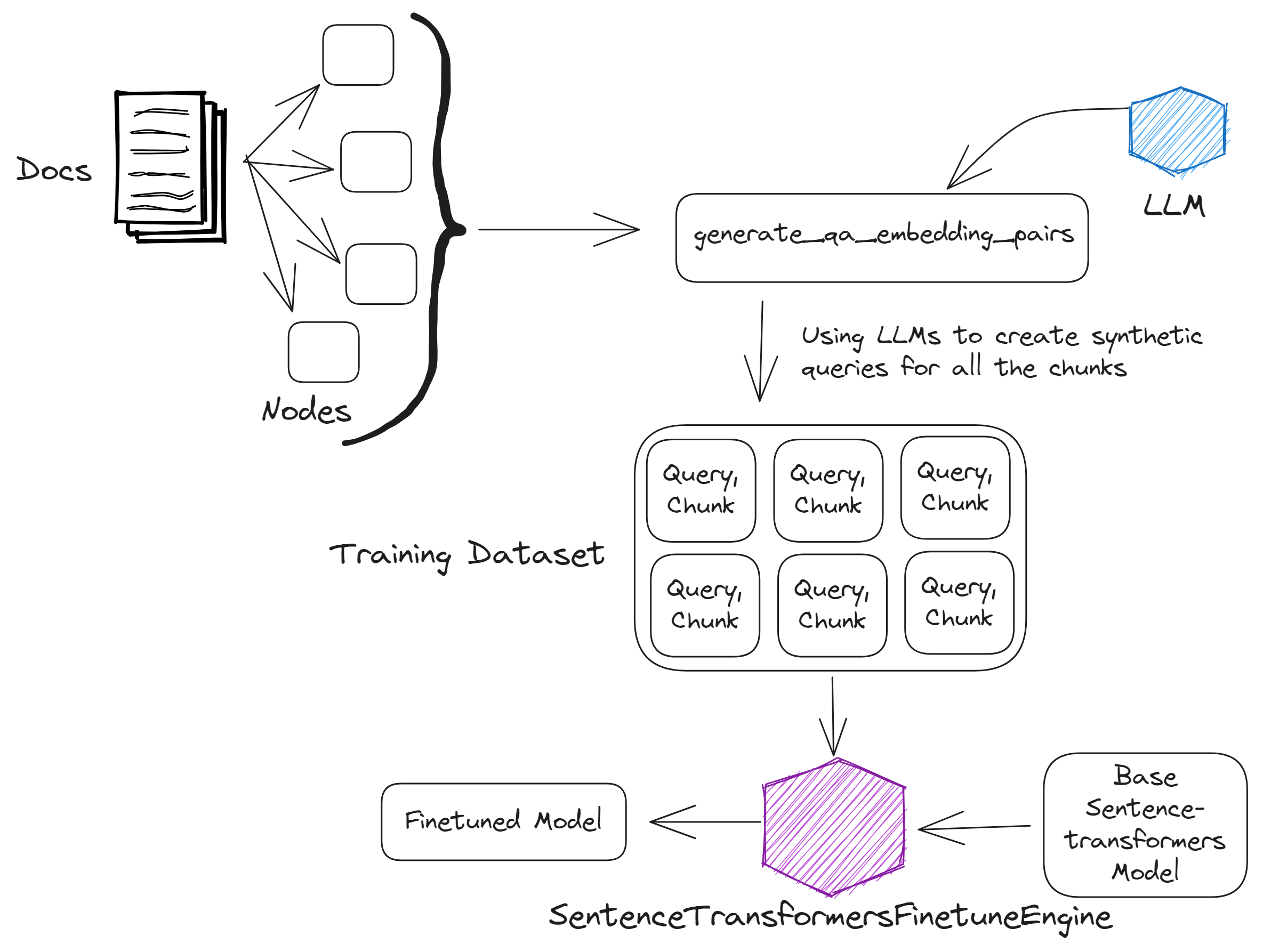
Embedding Finetuning
Finetuning means updating the model weights themselves over a set of data corpus to make the model work better for specific use-cases.
E.g. for embedding ArXiv papers, we want the embeddings to align semantically with the concepts and not filler words like “This paper is about…”.
LlamaIndex has guides on how to finetune embeddings in different ways:
- finetune the embedding model itself (only sentence transformers)
- finetune an adapter over any black-box embedding model (check here)
Steps for finetuning embeddings
3 Steps for finetuning embeddings:
- Prepare the data via generate_qa_embeddings_pairs()
- finetune model via SentenceTransformersFinetuneEngine
- Evaluate the model
Prepare the data
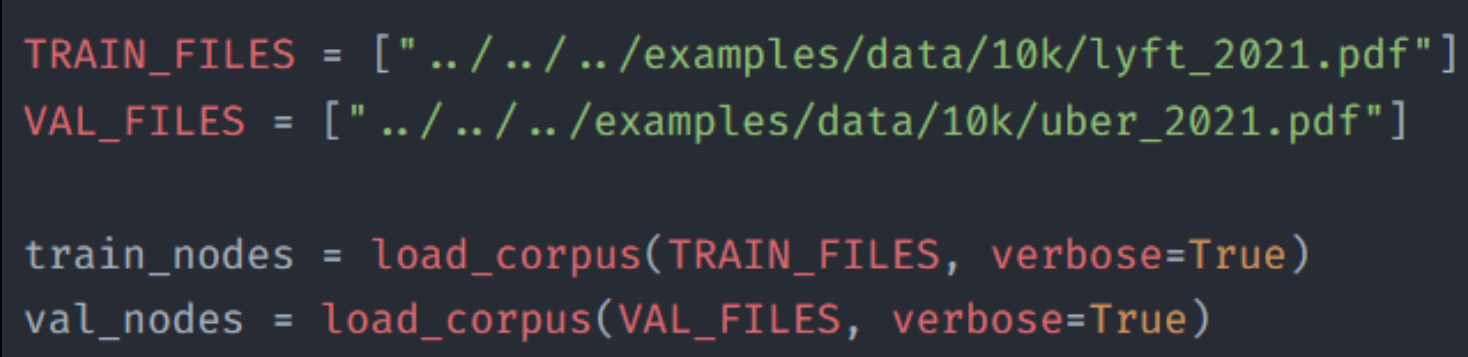
Here we use two pdfs: lyft.pdf and uber.pdf.
we’ll use lyft.pdf to create the training set and evaluate the finetuned model using evaluation set created from uber.pdf.
we create nodes from both training and evaluation pdfs.
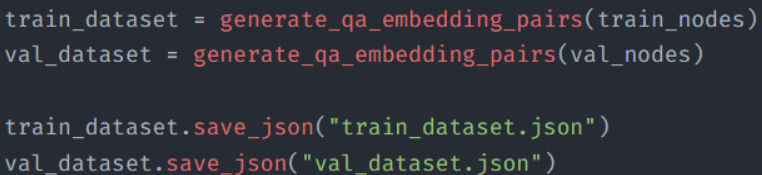
Next we use generate_qa_embedding_pairs() to create the training and evaluation datasets from the nodes.
For each chunk, synthetic queries are created for that chunk via LLMs.
Each pair of (generated question, text chunk used as context) becomes a datapoint in the datasets.
Finetune the model
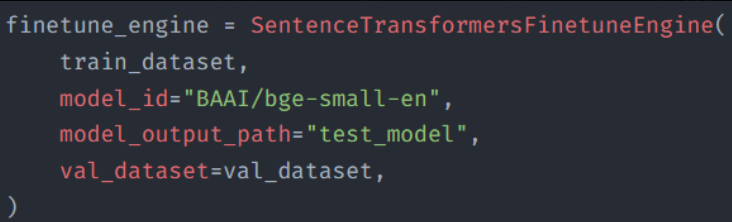
Next we use the SentenceTransformersFinetuneEngine to create the finetuning engine.
We pass it the necessary parameters like the train and evaluation dataset, model to finetune, path to output the finetuned model etc.
Finally, we finetune it using the engine created before and evaluate the new model comparing it with the base model and OpenAIEmbeddings

Evaluation
In the hit rate metric, new model performs significantly well from the base model it was finetuned on and even performs almost as good as openai embedding model.
More on finetuning and the evaluation method in the official docs here
Conclusion
The main drawback here is that every time we finetune a model we need to re-embed our entire data corpus.
Also we can only finetune Sentence transformer models.
If you don’t wanna re-embed every time after fintuning and you wanna use one of the black-box models like ada, then check out Adapter Finetuning
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter