A critical part in retrieval-augmented generation (RAG) is the Retrieval part where it gets the relevant documents based on user’s question.
Typically, the retrieved documents are plugged into the context in descending order of the vector similarity score.
Turns out that’s not the best way, specially when the number of retrieved documents is above 10.
The Issue
In the context window of LLM prompt, we put the most similar documents at the top, and least similar ones at the bottom.
But LLMs tend to ignore documents at the middle of its context. Hence, this is where we should put the least similar ones, not at the bottom.
Performance is often highest when relevant info occurs at the beginning or at the end of the context
Lost-in-the-middle Paper
This research paper shows that LLMs show substantial performance degradation when
- LLMs must access relevant info in the middle part of the context
- And also as the input grows longer (even for longer context models)
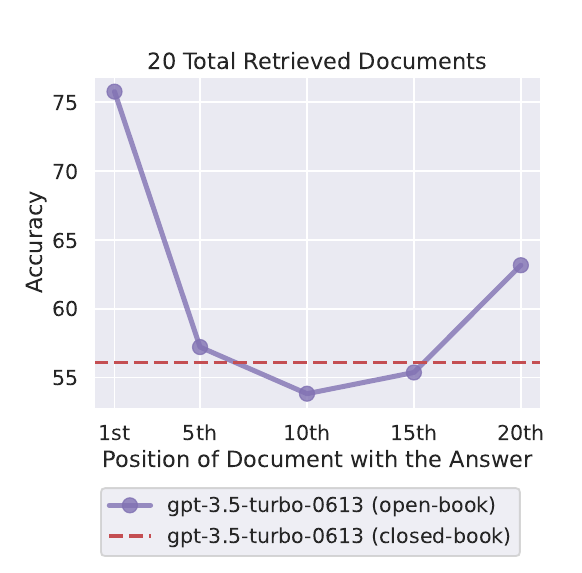
Here on x-axis we have the position of the document that contains user’s answer. And y-axis shows the accuracy of the response.
We can see the accuracy is better if the document containing the correct answer is near the top or bottom of the context.
LLMs get more lost in the middle as the input gets longer and longer. (10+ retrieved docs)
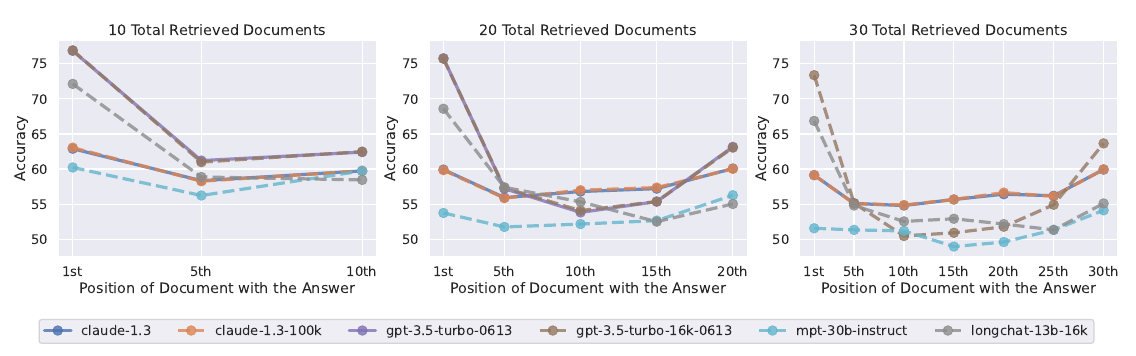
We can see even the longer context models don’t solve this issue. Hence, they are not necessarily better at reasoning over longer input contexts yet.
LongContextReorder
LangChain tries to address this issue by re-ordering the documents after retrieval.
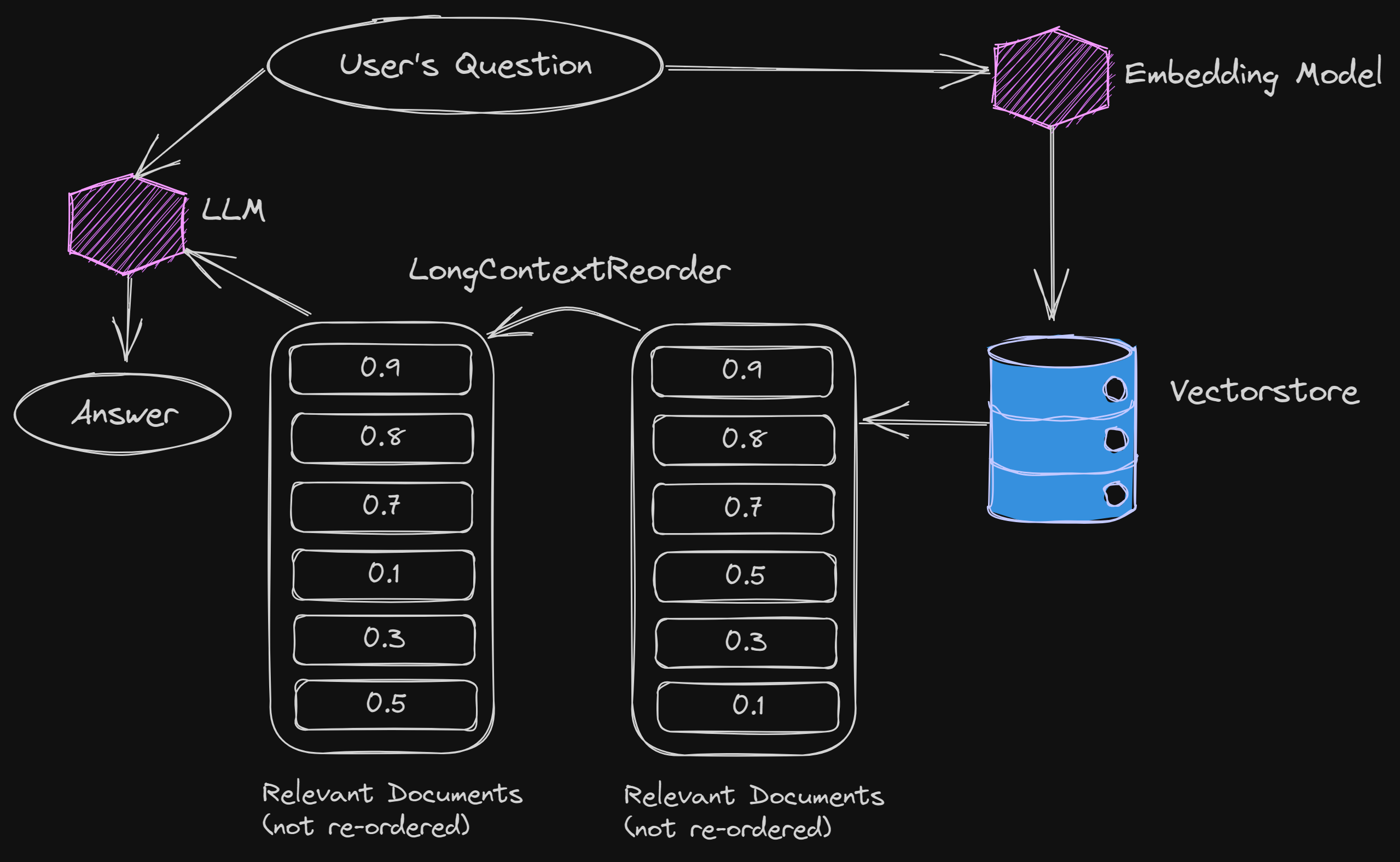
It puts the most similar ones at the top, and then the next few ones at the end, and the least similar ones in the middle.
In this way, the least similar ones will be in the place where the LLMs tend to get lost anyway.
LangChain
LongContextReorder
automatically does this.
We create any retriever as usual. And then get the relevant documents using
the get_relevant_documents() method of that retriever.
This returns the documents in the descending order of their similarity score.
Next we pass these documents to an instance of the LongContextReorder() and
get the re-ordered docs where the least relevant ones are at the middle.
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
And that’s it. With a simple re-ordering, you might get better results from your RAG pipeline with many (10+) retrieved documents.
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter