Small vs Large Document chunks
For Retrieval Augmented Generation (RAG), we split the raw text into multiple chunks and embed them using an embedding model (e.g. OpenAI Embeddings).
Then we use a retriever to retrieve the most relevant chunks to user’s query and feed them chunks to the LLM alongside the input.
But what should be the ideal length of each chunk? What’s the sweet spot?
The smaller the chunk size, the more accurately they reflect their semantic meaning after embedding
But the issue with smaller chunks is that, they might sound out of context.
When these smaller chunks are retrieved and plugged into the LLM input, it could be difficult for the LLM to find the answer to the user’s query properly without having the bigger picture for each of those small chunks.
What if we could use the smaller chunks (with better semantic meaning) for vector-embedding-similarity-search, but provide the larger chunks (from where the corresponding smaller chunks originated) with full context to the LLM input?
This is exactly what LangChain
ParentDocumentRetriever
does.
ParentDocumentRetriever
Let’s walk through the example code from LangChain’s website. I’ll explain how
the ParentDocumentRetriever works along the way.
Two splitters instead of one
Previously we only used one TextSplitter to split the raw text into multiple
documents.
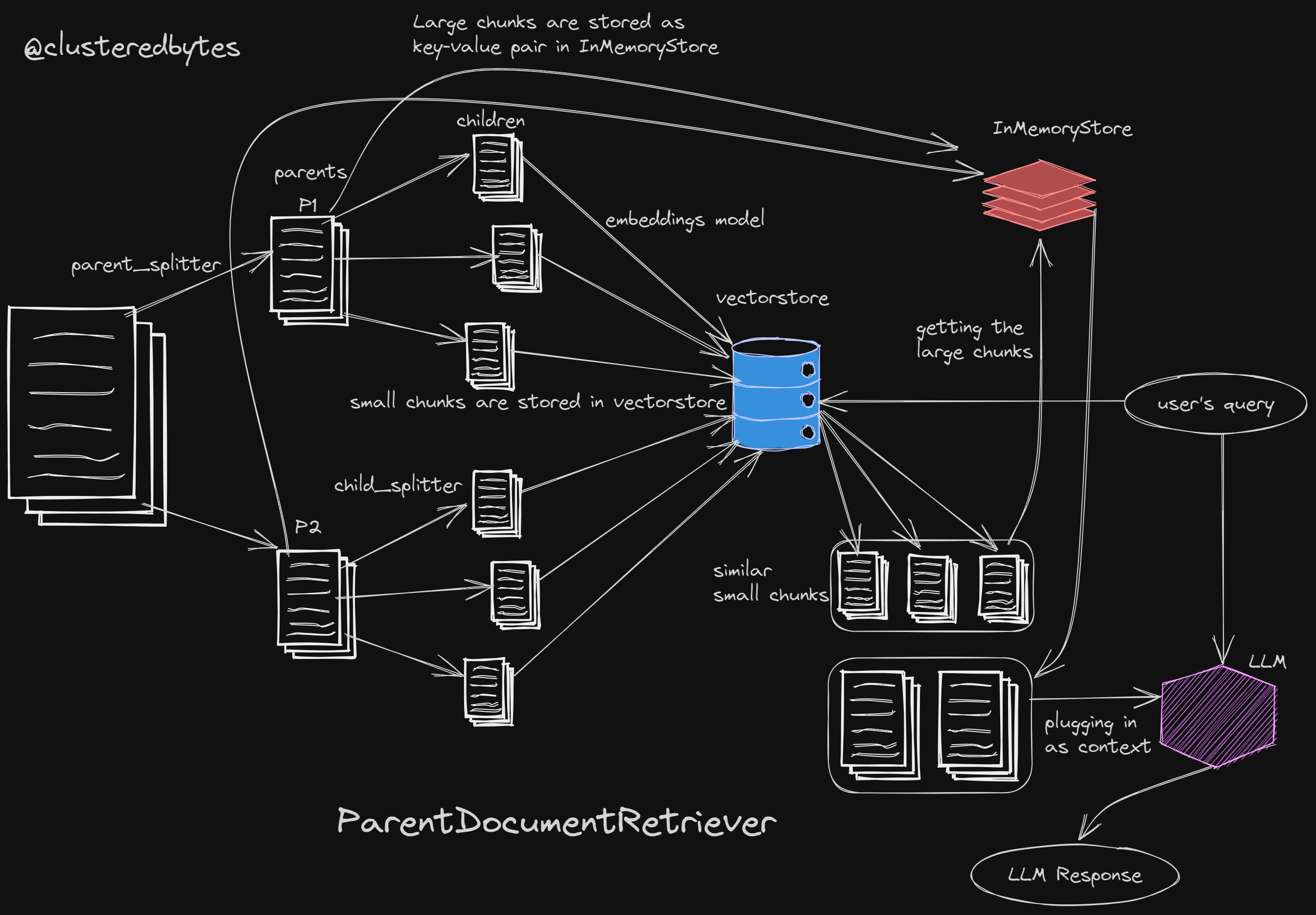
Now we need two of them. One for the larger chunks with more context (let’s call these larger chunks parent or just docs) and another splitter for the smaller chunks with better semantic meaning (let’s call these smaller chunks children or sub docs)
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
Storing both larger and smaller chunks
Now let’s create the vectorstore for storing the smaller chunks and an
InMemoryStore docstore to store the larger chunks.
vectorstore = Chroma(collection_name="split_parents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
vectorstores are used to store embeddings. And as we’re only embedding the
smaller chunks (as they capture better semantic meaning after embedding them),
we use vectorstore to only store the smaller chunks, not the larger ones.
For the larger ones tho, we use InMemoryStore. It’s like a dictionary type
KEY-VALUE pair data structure, that stays in the memory while the program is
running.
In the InMemoryStore
- Each key is a unique uuid for each large chunk
- Each value is the actual text content of the corresponding large chunk
In the vectorstore
- For each embedding of the smaller chunks, we store that unique uuid of the parent large chunk as a metadata. This large chunk is from where this small chunk is originated.
Create the ParentDocumentRetriever
Now let’s create the ParentDocumentRetriever
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
we pass the following arguments to the Constructor:
vectorstore: the vectorstore where the embeddings for the small chunks will be storeddocstore: where the larger chunks will be stored as KEY-VALUE pairschild_splitter: the text splitter to use on the small chunksparent_splitter: the text splitter to use on the large chunks
Adding the documents
retriever.add_documents(docs)
The following happens under the hood when the add_documents() method is
called:
- the
docsis split into large chunks usingparent_splitter - For each large chunk above
- a unique uuid is generated
- the Key-Value pair of that uuid and the large chunk is stored in the
docstore - then that larger chunk is further split into smaller chunks using
child_splitter - all these smaller chunks are then added to the
vectorstore - while adding, the
parent_idmetadata for each of these smaller chunks is set to that unique uuid of their parent large chunk
After adding, we can see there are 66 keys in the store. So 66 large chunks have been added.
len(list(store.yield_keys()))
# outputs 66
sub_docs = vectorstore.similarity_search("justice breyer")
# only returns small chunks
Also, if we apply similarity search on the vectorstore itself, we’ll get the small chunks only.
Retrieving relevant documents
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
# outputs 1849, which ensures we're indeed getting larger chunks as final output
The following happens when we call get_relevant_document() on
ParentDocumentRetriever 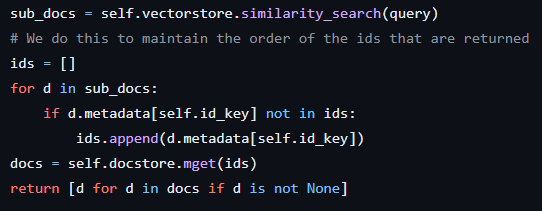
-
First all the small chunks are fetched from the
vectorstore -
Then we iterate over those small chunks in the order they’re returned by the
vectorstore- For each small chunk, we add its parent large chunk’s id to a list
-
Then using the parent ids as keys, we get the list of large chunks from the
docstoreand return those.
Thus we use small chunks (with better semantic meaning) for vector similarity matching and return their corresponding larger chunks that have the bigger picture and more context.
Hopefully the ParentDocumentRetriever will help you to get better set of
relevant documents while using LangChain for Retrieval Augmented Generation
(RAG).
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter