Embeddings
One painful issue while using embeddings to retrive relevant documents is that:
- the returned documents might vary with small changes in the query.
- e.g. using different wording (“what does the course say about regression?”)
- using diffent perspectives (“what is being discussed in the course regarding regression?”) etc.
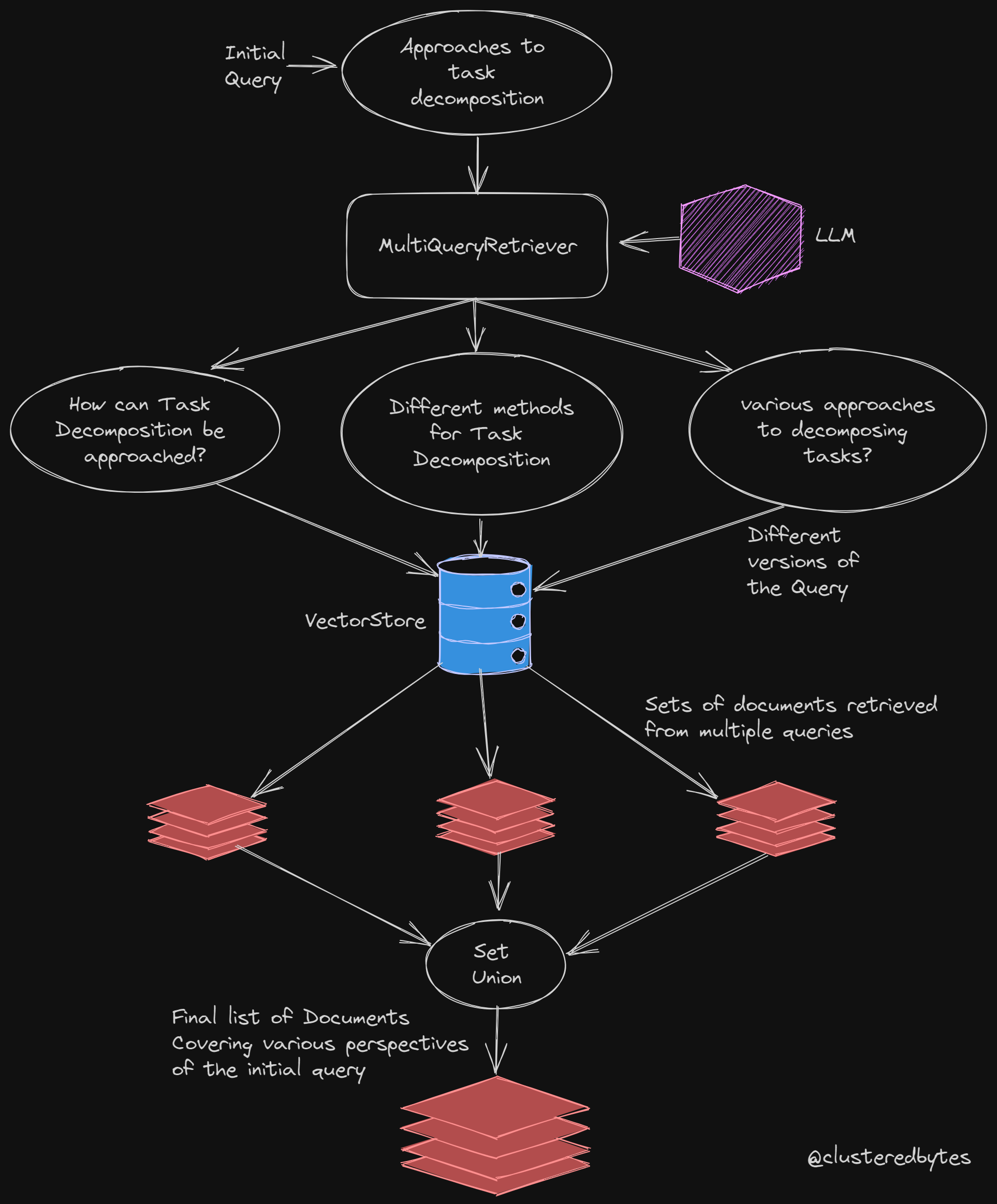
MultiQueryRetriever
MultiQueryRetriever
tries to address this issue with the help of Language Models.
- From user’s query, it generates multiple similar query, trying to cover various different perspectives.
- For each of those generated queries, it get’s a list of relevant documents.
- Then combines that list of documents.
Using the Default MultiQueryRetriever
Now let’s look at an example. This is the example that LangChain uses.
-
Normally we create a
vectorstorefrom the text splits and embedding modelfrom langchain.vectorstores import Chroma chroma_store = Chroma.from_documents(texts, embeddings) -
Then using that
vectorstorewe created aretriever, and called theget_relevant_documents()of that retrieverretriever = db.as_retriever()
-
Now the difference is, we create the retriever using
MultiQueryRetriever.from_llm()method passing the LLM to be used to multiple query generation.llm = ChatOpenAI(temperature=0) multi_retriever = MultiQueryRetriever.from_llm( retriever=vectordb.as_retriever(), llm=llm ) -
Let’s use our multi_retriever to find relevant documents now.
question = "What are the approaches to Task Decomposition?" unique_docs = multi_retriever.get_relevant_documents(query=question)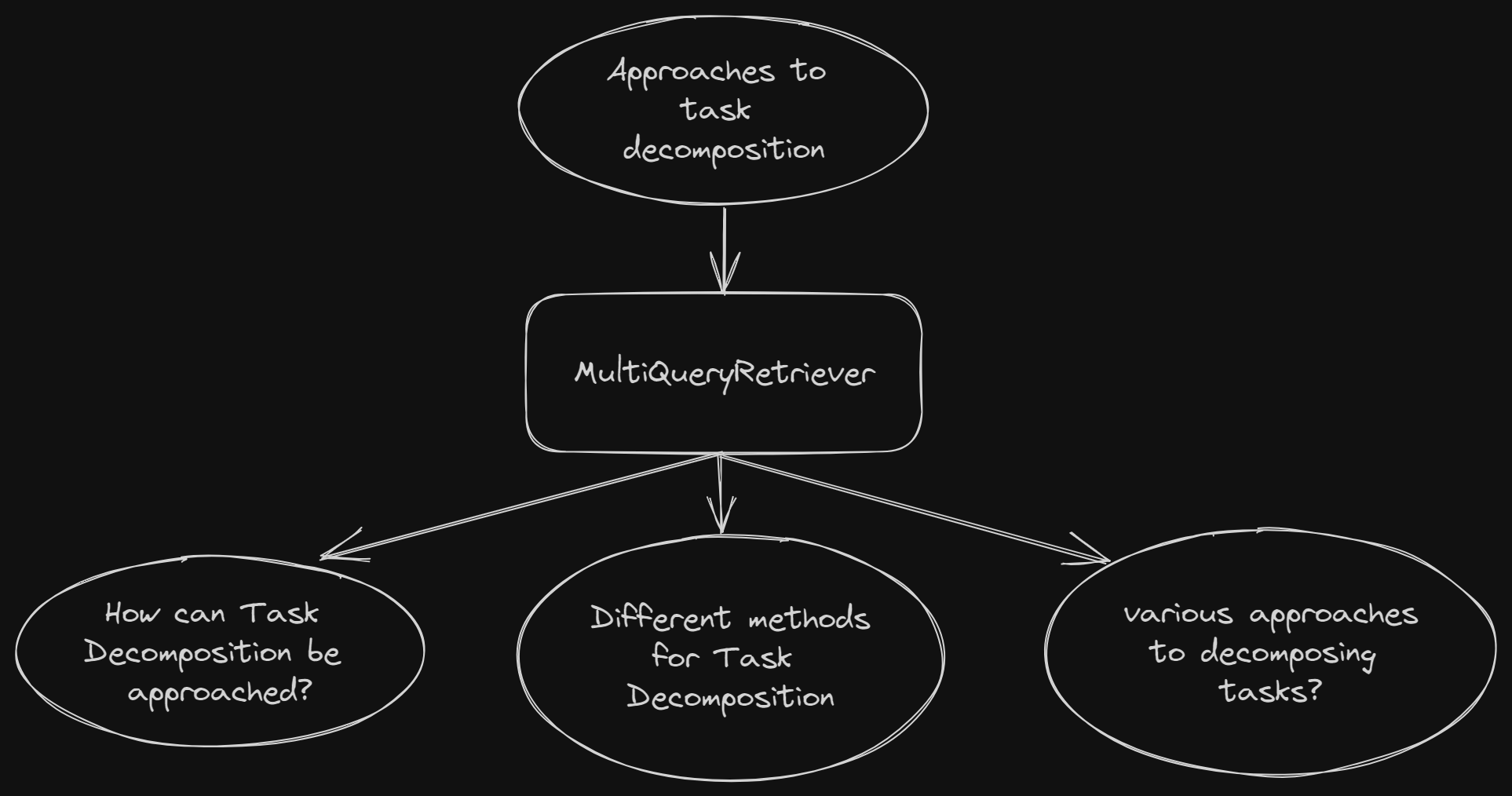
Custom MultiQueryRetriever
We can supply our own prompt and output parser.
It allows us to customize how we want the LLM to generate multiple queries based on our specific usecase.
We’re gonna need to create an LLMChain with our prompt and output parser.
-
Prompt
QUERY_PROMPT = PromptTemplate( input_variables=["question"], template="""You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions seperated by newlines. Original question: {question}""", ) -
Output parser - extracts queries separated by
\nclass LineListOutputParser(PydanticOutputParser): def __init__(self) -> None: super().__init__(pydantic_object=LineList) def parse(self, text: str) -> LineList: lines = text.strip().split("\n") return LineList(lines=lines) -
Next, to create the custom
MultiQueryRetriever, unlike the default one, where we gave thellm, this time we need to give ->- the
LLMChainfor the custom MultiQueryRetriever - and the parser_key for the Output Parser
retriever = MultiQueryRetriever( retriever=vectordb.as_retriever(), llm_chain=llm_chain, parser_key="lines" ) # "lines" is the key (attribute name) of the parsed output - the
-
Finally we call the
get_relevant_documents()method of the retriever as usual.
Hopefully the MultiQueryRetriever will help you to get better set of relevant
documents via capturing the context from various different angles and
perspectives.
But there’s another dilemma.
While chunking,
- should we do smaller chunks to percisely reflect their meaning?
- or larger chunks to cover it’s entire context?
Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter