During RAG, a very important step is selecting the retrieval granularity of the documents. The choice of the retrieval unit significantly impacts both retrieval and response synthesis.
Traditional approaches are chunking the documents by fixed length passages or sentences. But they’ve their limitations.
The “Dense X Retrieval” paper introduces a novel retrieval unit, Proposition
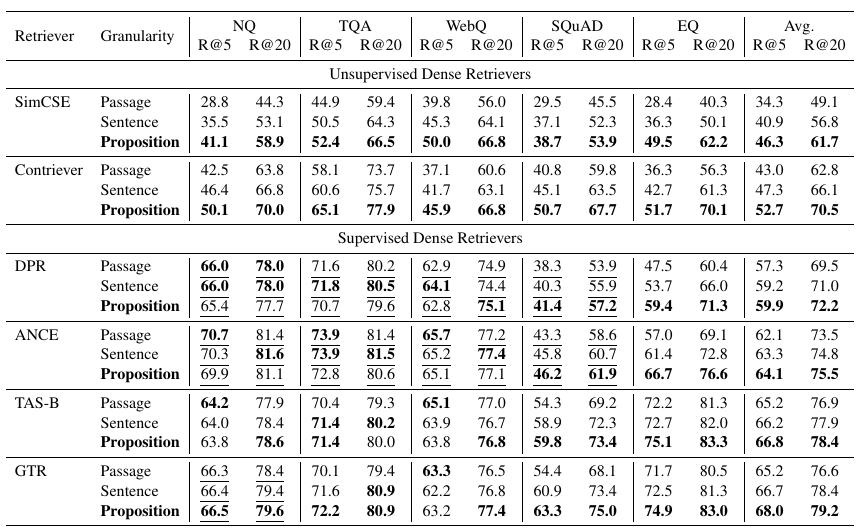
Proposition based retrieval significantly outperforms both sentence and passage based retrieval.
Passage based retrieval
Pros
- Provides more context to the llm
- More backgroud info
Cons
- Often includes extraneous details
- Hence distracts the LLM during response synthesis
Sentence based retrieval
Pros
- Short
- Fine-grained
Cons
- Lacks context
- Sentences can still be complex or compounded

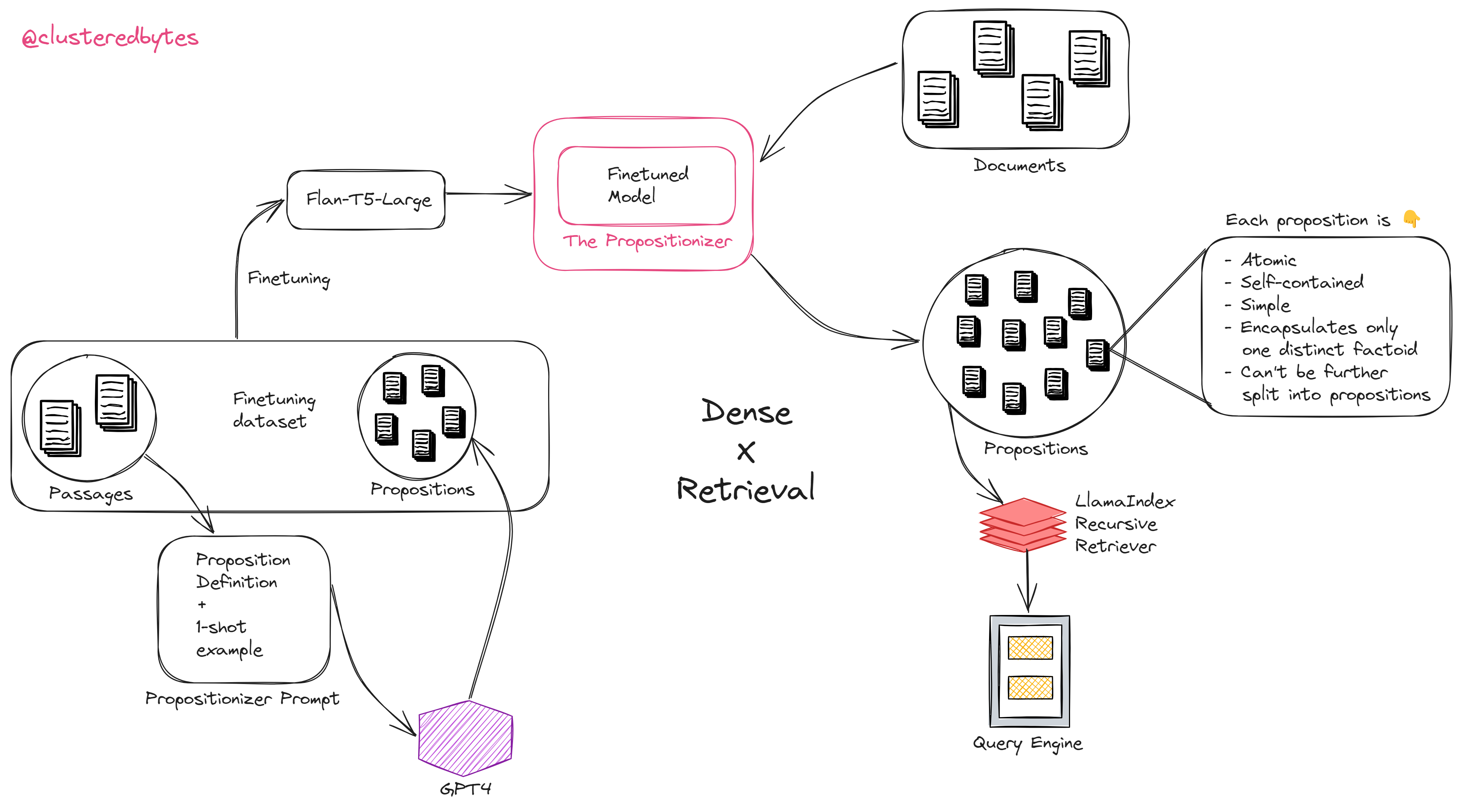
Meet Propositions
A proposition is an atomic, self-contained text encapsulating a distinct factiod, written in simple natural language format.
Proposition encapsulate only one contexualized atomic fact, it cannot be further split into separate propositions.
According to the paper, if we use propositions as the retrieval unit, then retrieved texts are condensed with information relevant to the query. It minimizes the inclusion of extraneous, irrelevant info.
Thus it improves the synthesized response by injecting better quality info into the final LLM prompt.
Propositions are both compact and rich in context. Hence they have the highest density of query-relevant information.
Generating propositions
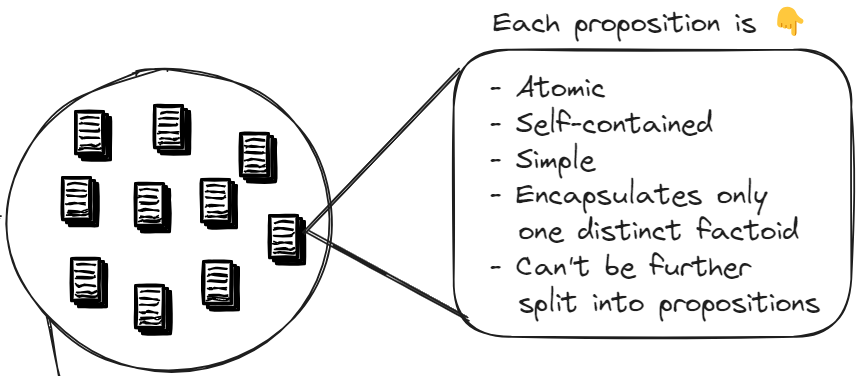
The paper also shows an amazing method to create these propositions. It involves 2 steps.
First, GPT-4 is prompted with the definition of a Proposition and also with a 1-shot example. Then GPT-4 with that prompt, is used on 40K passages to create propositions on all of them.
These data is them used to fine-tune a Flan-T5-Large model. The authors call this fine-tuned model “The Propositionizer”
The paper also introduced FACTOIDWIKI, which is the propositions index created by the propositionizer on the Wikipedia dump till 2021.
Dense X Retriever LlamaPack
Logan from LlamaIndex created an amazing LlamaPack that lets you get up and running with the Dense X Retriever in no time.
It handles:
- Generating the propositions using LLM
- Creating the vector index
- Creating the retriever (Recursive retriever in this case) and the query engine
from llama_index import SimpleDirectoryReader
from llama_index.llama_pack import download_llama_pack
# download and install dependencies
DenseXRetrievalPack = download_llama_pack(
"DenseXRetrievalPack", "./dense_pack"
)
documents = SimpleDirectoryReader("./data").load_data()
# uses the LLM to extract propositions from every document/node!
dense_pack = DenseXRetrievalPack(documents)
response = dense_pack.run("What can you tell me about LLMs?")
print(response)
One thing to be carefull is that for really large data corpus, generating the propositions can be quite expensive. For that, you can use a fine-tuned model like the authors.
Comparison
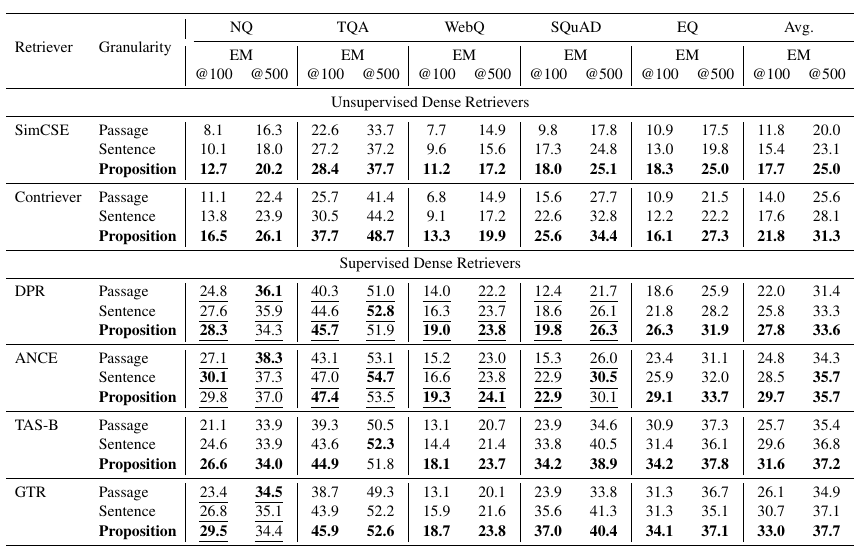
The paper evaluates proposition-based retrieval in two ways, during retrieval and during response synthesis.
The retrieval evaluation score is calculated based on the maximum similarity score between the query and all sentences or propositions.
The response synthesis evalution is performed by passing the first l(100 or 500) words to the LLM and compare the generated response with the ground truth.
Better LLM output using propositions
The LLM gives better quality answers if propositions are injected as relevant information compared to injecting passages or sentences.
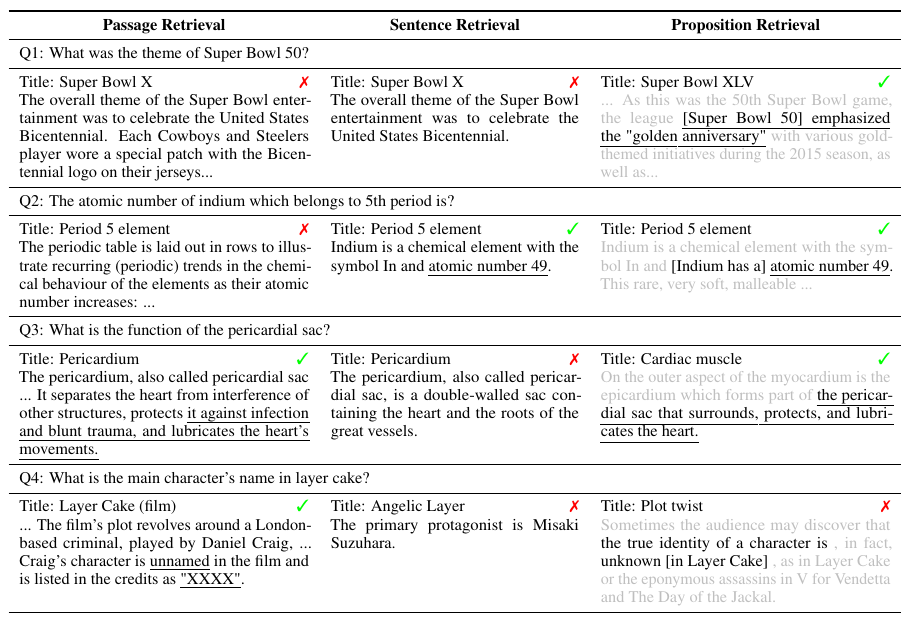
Out of the three, propositions has the highest density of relevant info.
E.g. For a fixed retrieved word budget (say 100-200 words), we can fit roughly 10 propositions, 5 sentences, or 2 passages. So when providing the first 100-200 words from retrieved document, the LLM that was using propositions generated better answers.
Thus propositions give LLM more info, with better context.
Conclusion
Thus using propositions as retrieval unit significantly outperforms both sentence and passage based retrieval for retrieval accuracy and LLM response quality.
Checkout the paper for more details.
Also checkout the (LlamaPack by Logan)[https://llamahub.ai/l/llama_packs-dense_x_retrieval?from=all]
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter