What if there was a discord bot that would:
- Listen to your server conversations
- Continuously learn from them
- Answer your questions from the entire server.
Introducing LlamaBot 🔥🚀 An open-source Discord bot that does all that, created using LlamaIndex.
In this guide, I’ll walk you through the entire process of building a full-fledged discord bot like this using LlamaIndex.
The bot is fully open-sourced. Here’s the GitHub repo: LlamaBot
Here’s the tech stack we’ll be using
- LlamaIndex as the RAG framework
- Google Gemini Pro as the LLm and Embedding model
- Qdrant cloud as the vectorstore
- discord.py to setup the bot logic
- Finally deploy it to Replit
It’s recommended to host this bot yourself for your server, but if you wanna try out first, you can invite the bot to your server through this link.
Let’s see how to build this bot from scratch 👇
Create a discord app
Go to this link to create a new app from Discord developer portal.
Next go to “Bot” from the left panel.
From the “Build-A-Bot” section you can set a username and logo for your bot.
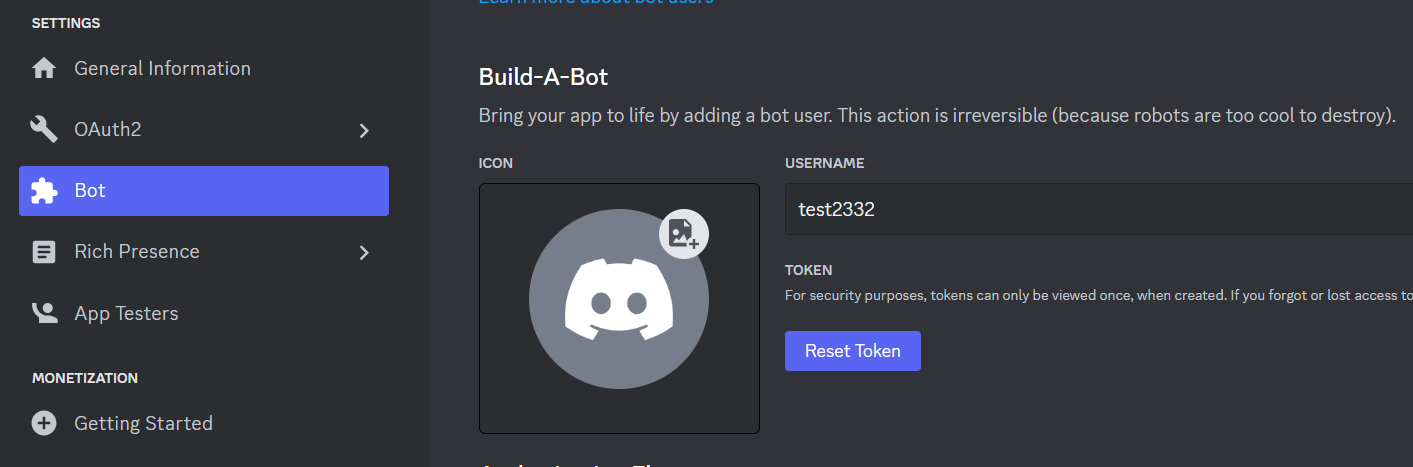
Bot permissions and OAuth
Click OAuth2 from left panel, next click URL Generator.
From scopes, now click ‘bot’
From Bot permissions, check “Send Messages” and “Read Messages/View Channels”
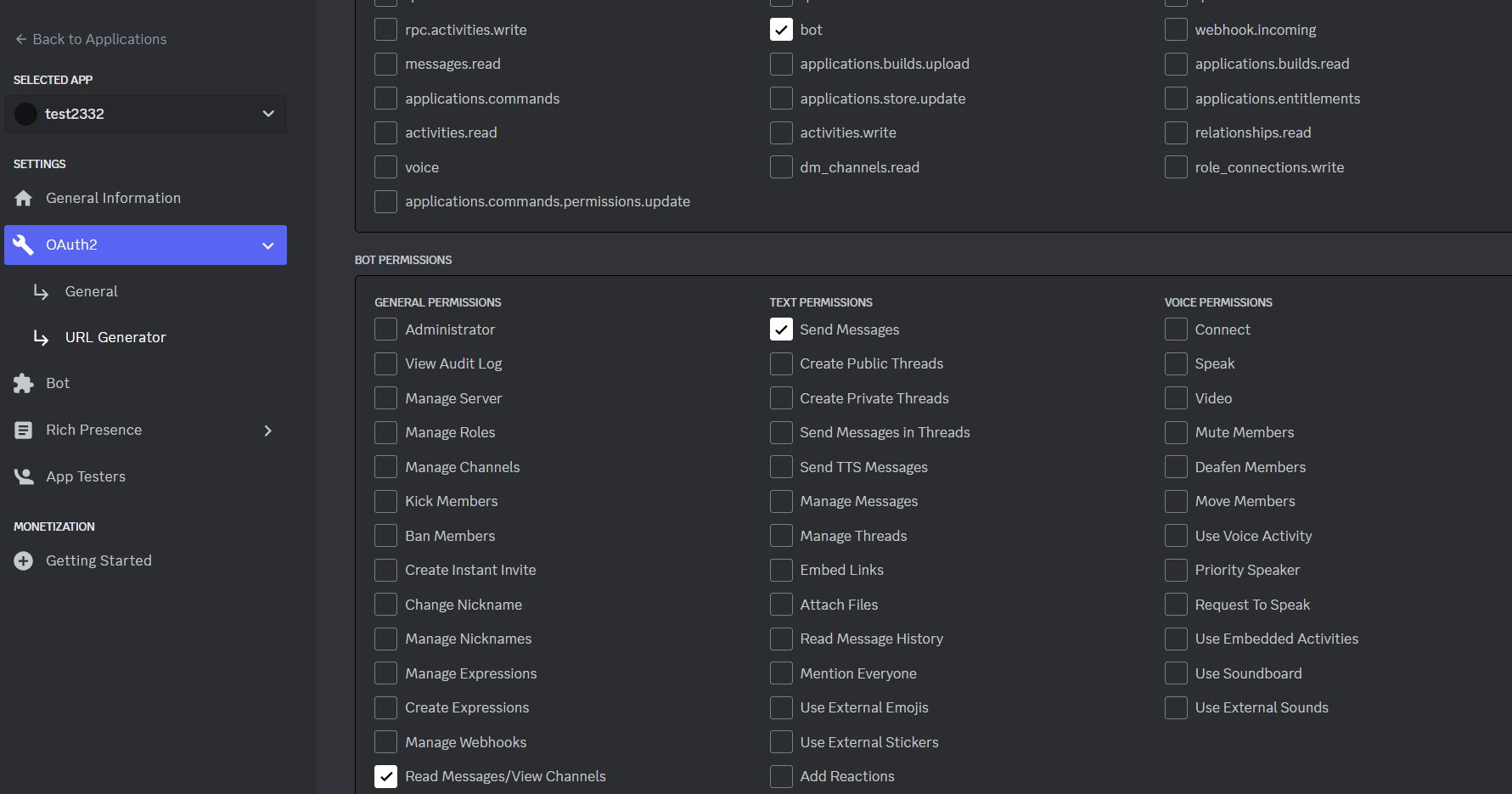
Get Bot API key
Click “Bot” and then click the “Reset Token” button.
Now save the API key somewhere secure.
Project Setup
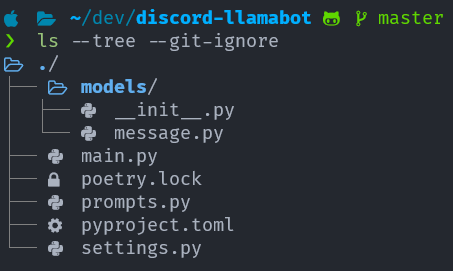
Here’s how we structure our project.
settings.py has the config of the bot.
prompts.py has the prompt of the bot.
main.py is where the main logic of the bot lives.
We also have some hidden file for logging(./logs/info.logs), persisting(./persist/) and environment variables(.env)
Environment variables
DISCORD_API_TOKEN='...' # For the bot API
QDRANT_KEY='...' # For Qdrant Cloud Vectorstore
QDRANT_URL='...' # For Qdrant Cloud Vectorstore
GOOGLE_API_KEY='...' # For Google Gemini Pro LLM and Embedding
We use these environment variables for our bot.
Dependencies
In our pyproject.toml we list our dependencies for the bot
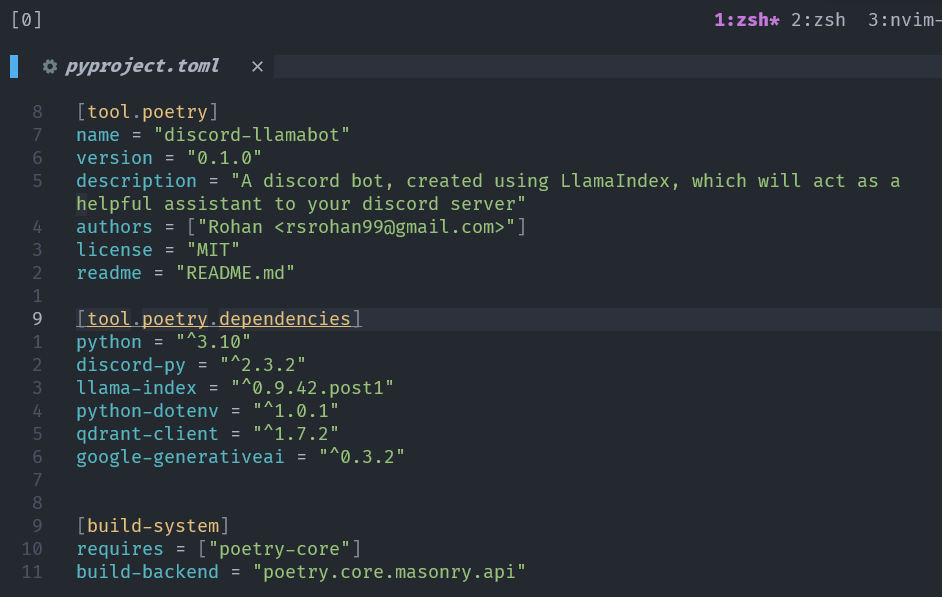
discord.py to build the logic of the bot
llama-index as our RAG framework
python-dotenv for environment variable management
qdrant-client for talk to Qdrant Cloud vectorstore
google-generativeai to use Gemini LLM and Embedding models
A Simple Discord Bot command
Let’s create a simple command first.
The command will be /ping and when we use this command, the bot will just say back ‘pong’
@bot.command()
async def ping(ctx):
"Answers with pong."
await ctx.send('pong')
Overview of the commands in our bot
Now that we know how to create basic commands, let’s see some of the commands our bot has:
async def listen(ctx):
"Llama will start listening to messages in this channel from now on."
global listening
listening[ctx.guild.id] = True
persist_listening()
logger.info(f"Listening to messages on channel {ctx.channel.name} of server: {ctx.guild.id} "
f"from {datetime.now().strftime('%m-%d-%Y %H:%M:%S')}")
await ctx.send('Listening to your messages now.')
@bot.command(
aliases=['s']
)
async def stop(ctx):
"Llama will stop listening to messages in this channel from now on."
global listening
listening[ctx.guild.id] = False
persist_listening()
logger.info(f"Stopped Listening to messages on channel "
f"{ctx.channel.name} from {datetime.now().strftime('%m-%d-%Y')}")
await ctx.send('Stopped listening to messages.')
The /listen and /stop commands are used to tell the bot to listen to or stop listening to conversations in the server.
The bot will only remember conversations that took place after /listen command was invoked.
Also note that how we created aliases for these commands (/l and /s)
async def forget(ctx):
"Llama will forget everything it remembered. It will forget all messages, todo, reminders etc."
forget_all(ctx)
await ctx.send('All messages forgotten & stopped listening to yall')
@bot.command(
aliases=['st']
)
async def status(ctx):
"Status of LlamaBot, whether it's listening or not"
await ctx.send(
"Listening to yall👂" if listening.get(ctx.guild.id, False) \
else "Not Listening 🙉"
)
The next two commands are /forget and /status
/forget commads deletes all memory of the bot from this server.
/status tells whether the bot is listening to conversations or not.
RAG
Ok now let’s get to the good bit, the RAG behind the bot and how we setup the RAG using various LlamaIndex abstractions.
LlamaIndex is the RAG framework we’ll be using for this bot.
It has some really useful abstractions that makes building RAG really easy while being super customizable to suit diverse scenarios.
In the next parts of thie guide, we’ll look into some of those abstractions and also customizations.
Prepare the Qdrant vectorstore
We first create the qdrant client instance through the url and api key. We also specify which collection to use.
# initialize qdrant client
qd_client = qdrant_client.QdrantClient(
url=settings.QDRANT_URL,
api_key=settings.QDRANT_API_KEY
)
qd_collection = 'discord_llamabot'
Next we create LlamaIndex QdrantVectorStore instance with the client and collection.
And then we wrap the vectorstore inside a LlamaIndex storage_context
vector_store = QdrantVectorStore(client=qd_client,
collection_name=qd_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
Gemini LLM and Embedding setup
I decided to use Gemini Pro as the LLM and their new embedding for this project.
But you can use whichever llm or embed model you want.
Thanks to LlamaIndex, it’s basically a one line code change 🔥
from llama_index.llms import Gemini
from llama_index.embeddings import GeminiEmbedding
llm=Gemini()
embed_model = GeminiEmbedding()
service_context = ServiceContext.from_defaults(
embed_model=embed_model,
llm=llm
)
We also wrap the llm and the embedding model inside a service_context
Create the VectorStoreIndex
Here we create a LlamaIndex VectorStoreIndex
A VectorStoreIndex:
- Stores the nodes and their embedding in a vectorstore (Qdrant in our case)
- During query time, retrieves top-k nodes and generates a response using the LLM.
from llama_index import VectorStoreIndex
index = VectorStoreIndex(
[],
storage_context=storage_context,
service_context=service_context
)
Here we pass and empty list as we’re gonna incrementally add messages to our vectorstore.
We pass the storage and service context that wraps the vectorstore, llm, embed model to use for this index.
Messages Ingestion
While the bot is listening, whenever a new message is posted that is not a bot command or a bot reply, we do the following:
- Create a LlamaIndex
TextNode - Add relevant metadata
- Specify which metadata to ignore while embedding the node or injecting the node to the LLM
- Then insert the node to our previously created
VectorStoreIndex
node = TextNode(
text=msg_str,
metadata={
'author': str(who),
'posted_at': str(when),
'channel_id': message.channel.id,
'guild_id': message.guild.id
},
excluded_llm_metadata_keys=['author', 'posted_at', 'channel_id', 'guild_id'],
excluded_embed_metadata_keys=['author', 'posted_at', 'channel_id', 'guild_id'],
)
index.insert_nodes([node])
The bot is basically saving this message to its memory for future reference.
We keep the guild_id in the metadata so that we don’t mix up messagses from different servers.
To give the LLM better context during response generation, we store all messages, including those we don’t store in the vectorstore, in a separate message store.
messages[message.guild.id].append(Message(
is_in_thread=str(message.channel.type) == 'public_thread',
posted_at=when,
author=str(who),
message_str=msg_str,
channel_id=message.channel.id,
just_msg=message.content
))
Answering queries
We first get last few messages of the channel from where the bot was invoked.
This is to ensure better context and background for the LLM.
Next we use the partial_format() function of LlamaIndex to inject these info in the prompt:
channel_id = ctx.channel.id
thread_messages = [
msg.message_str for msg in messages.get(ctx.guild.id, []) if msg.channel_id==channel_id
][-1*settings.LAST_N_MESSAGES:-1]
partially_formatted_prompt = prompt.partial_format(
replies="\n".join(thread_messages),
user_asking=str(ctx.author),
bot_name=str(bot.user)
)
MetadataFilters
Next we use MetadataFilters of LlamaIndex to ensure that we only retrieve messages from this server, and also ensure that retrieved messages are not bot messages.
filters = MetadataFilters(
filters=[
MetadataFilter(
key="guild_id", operator=FilterOperator.EQ, value=ctx.guild.id
),
MetadataFilter(
key="author", operator=FilterOperator.NE, value=str(bot.user)
),
]
)
PostProcessor on nodes
From the retrieved nodes, we wanna sort them based on recency, so that the LLM prioritizes information from the most recent messages.
We use LlamaIndex FixedRecencyPostprocessor for this.
postprocessor = FixedRecencyPostprocessor(
top_k=20,
date_key="posted_at", # the key in the metadata to find the date
service_context=service_context
)
Remember while ingesting messages to vectorstore, we added a posted_at metadata, we’ll use that metadata to sort the retrieved messages.
QueryEngine
Next we combine all of these filters, postprocessors etc. to create a query_engine
query_engine = index.as_query_engine(
service_context=service_context,
filters=filters,
similarity_top_k=20,
node_postprocessors=[postprocessor])
query_engine.update_prompts(
{"response_synthesizer:text_qa_template": partially_formatted_prompt}
)
We also update the default prompt with our custom, partially formatted prompt that we created earlier.
Querying
Now lets perform the query.
But before that we need to do one thing.
Sometimes the last question itself might lack relevant context and background, especially in a chat-interface like Discord.
So we’ll not actually use the embedding of only the last query to retrieve relevant nodes, we’ll use embedding from the last few messages.
We can easily do that with LlamaIndex QueryBundle
replies_query = [
msg.just_msg for msg in messages.get(ctx.guild.id, []) if msg.channel_id==channel_id
][-1*settings.LAST_N_MESSAGES:-1]
replies_query.append(query)
return query_engine.query(QueryBundle(
query_str=query,
custom_embedding_strs=replies_query
))
Here we’ll use the query_str to be the last message. But the vector embedding that’ll be used to retrieve relevant nodes, will actually use the last few chat messsages.
Forgetting memory
Anytime we want, we can tell our LlamaBot to forget everything it knows about our server.
When we invoke the /forget command, it -
- Stops listening to messages
- Deletes all messages from the message store
- Deletes all embedding of messages of this server from the vectorstore
messages.pop(ctx.guild.id)
listening.pop(ctx.guild.id)
qd_client.delete(
collection_name=qd_collection,
points_selector=rest.Filter(
must=[
rest.FieldCondition(
key="guild_id", match=rest.MatchValue(value=ctx.guild.id)
)
]
),
)
What’s Next?
Great!! We have out LlamaBot, listening to our conversations in our server, keeping them in the memory and answering our queries.
There’re many features we could add to enhance our Llamabot. For example:
- Multi-modal RAG, where it understands from images sent to the server
- Task management for users in the server
- Upload files as message content, and ask questions about them.
- Listen to voice channels and summarize meetings
And a whole lot more…
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter