Better-Resume
A multi-agent resume optimizer using LlamaIndex AgentWorkflow
The goal of this project:
- Create a multi-agent system
- That takes a job posting URL and an existing resume
- Does a thorough analysis of the job posting and the existing resume
- Generates a custom resume tailored specifically for that job posting so that it stands out.
- The optimized resume highlights the skills and experiences that are most relevant to the job posting.
- Render the resume
- Iteratively updates the rendered resume from user’s feedback, including color scheme customization.
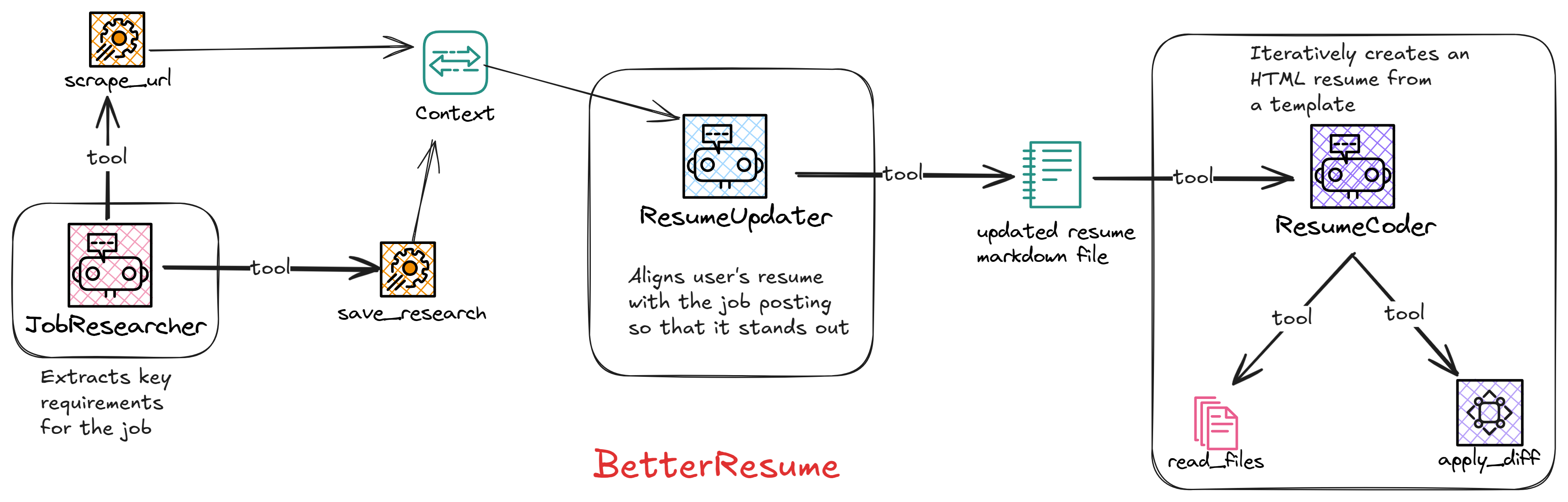
In the first part, we looked at the agents that perform the job research and updated the resume.
In this second part, we’ll see how the coding agent works, that iteratively renders and updates the optimized resume.
Link to the GitHub Repository: Better-Resume
Demo 👇
Workflow as a tool
In the first part, we created a workflow that optimizes and generates a resume in markdown.
First we’ll encapsulate that workflow into a tool for our main workflow.
async def generate_resume_markdown(
resume_file_path: Annotated[
str,
'The path to the user\'s existing resume file, use "resume.pdf" if the user has not provided a file path.',
],
job_posting_url: Annotated[str, "The URL of the job posting. Required."],
) -> str:
"""
Useful for generating the resume markdown file from user's existing resume and job posting url.
Only use this tool if user explicitly asks to generate the resume markdown file.
"""
try:
update_resume_workflow = get_resume_updater_workflow(
job_posting_url, resume_file_path
)
handler = update_resume_workflow.run(
user_msg="tailor my resume for the provided job application",
)
await log_events(handler)
await handler
if os.path.exists("html_resume"):
shutil.rmtree("html_resume")
shutil.copytree("html_resume_template", "html_resume")
print("\nDeleting old html_resume folder and copying the new one...\n")
return "Resume markdown file generated successfully."
except FileNotFoundError:
return "File not found."
except Exception as e:
return f"An error occurred: {str(e)}. Try again..."
This tool -
- takes the job posting URL and the existing resume file path
- creates the
update_resume_workflowusing the workflow factory we’ve seen in the first part - then runs the workflow
- finally it copies the
html_resume_templatefolder for theCoding Agent
read_file tool
async def read_file(
file: Annotated[str, "The file to read, either 'html' or 'css'"],
) -> str:
"""
Useful for getting the contents of either the html or css file. shows the line numbers, which are used for applying diff.
"""
try:
base_dir = "html_resume"
print(f"\nGetting contents from file: {file}...\n")
file_to_read = os.path.join(
base_dir, "resume.html" if file == "html" else "style.css"
)
with open(file_to_read, "r") as f:
contents = f.readlines()
return "".join([f"{i + 1} | {line}" for i, line in enumerate(contents)])
except FileNotFoundError:
return "File not found."
except Exception as e:
return f"An error occurred: {str(e)}. Try again..."
This tool -
- reads the contents of either the
htmlorcssfile CodingAgentuses this tool to read the source code- it includes line numbers for fine-grain updates while applying diff.
read_markdown_resume tool
async def read_resume_markdown() -> str:
"""
Useful for getting the contents of the resume markdown file that will be used to populate the html template.
"""
try:
print("\nGetting contents from markdown resume file...\n")
with open("updated_resume.md") as f:
return f.read()
except FileNotFoundError:
return "Resume markdown file not found. use the 'generate_resume_markdown' tool to generate a new markdown resume."
except Exception as e:
return f"An error occurred: {str(e)}. Try again..."
The CodingAgent uses this tool to read the optimized resume contents for populating the template.
If the resume markdown file is not found, it prompts the agent to use the generate_resume_markdown tool to generate an optimized resume using the job posting URL and the existing resume.
apply_diff tool
async def apply_diff(
file: Annotated[str, "The file to apply diff, either 'html' or 'css'"],
search_content: Annotated[
str,
"The exact code to replace within start_line and end_line of the file. The code must match exactly including proper indendation.",
],
replace_content: Annotated[str, "The new code to replace the old code with."],
start_line: Annotated[int, "The line number of the first line of search_content"],
end_line: Annotated[int, "The line number of the last line of search_content."],
) -> str:
"""
Useful for applying a diff to a file using search and replace. You need to make sure that the code from start_line to end_line must exactly be the search_content. if unsure use read_file first.
"""
try:
print(f"\nApplying diff to {file} file...\n")
base_dir = "html_resume"
file_to_read = os.path.join(
base_dir, "resume.html" if file == "html" else "style.css"
)
with open(file_to_read, "r") as f:
lines = f.readlines()
start_line = int(start_line)
end_line = int(end_line)
main_content = "".join(lines[start_line - 1 : end_line])
normalized_main = re.sub(r"\s+", "", main_content)
normalized_search = re.sub(r"\s+", "", search_content)
# Check if the search content matches the specified lines
if normalized_search in normalized_main:
pattern = re.compile(r"\s*".join(map(re.escape, search_content)))
match = pattern.search(main_content)
if match:
content_to_replace = (
main_content[: match.start()]
+ replace_content
+ main_content[match.end() :]
)
content_to_replace = (
content_to_replace + "\n"
if content_to_replace[-1] != "\n"
else content_to_replace
)
# Replace the specified lines with the new content
lines[start_line - 1 : end_line] = content_to_replace.splitlines(
keepends=True
)
with open(file_to_read, "w") as f:
f.writelines(lines)
return f"Diff applied successfully to {file} file. Here is the updated code of {file}:\n\n{''.join([f'{i + 1} | {line}' for i, line in enumerate(lines)])}"
else:
return "Search content does not match the specified lines. Diff not applied. Please use the read_file tool and make sure to use the exact code and the correct start_line and end_line."
else:
return "Search content does not match the specified lines. Diff not applied. Please use the read_file tool and make sure to use the exact code and the correct start_line and end_line."
except FileNotFoundError:
return "File not found."
except Exception as e:
return f"An error occurred: {str(e)}. Try again..."
This tool -
- uses search and replace to apply a diff to a file (html or css)
- it takes the file name, search content, replace content, start line and end line as input
- it checks if the search content matches the specified lines
- if it does, it replaces the specified lines with the new content
- if it doesn’t, it returns an error message, prompting the
CodingAgentto use theread_filetool and make sure to use the exact code and the correct start line and end line.
CodingAgent
RenderResumeWorkflow = AgentWorkflow.from_tools_or_functions(
tools_or_functions=[
generate_resume_markdown,
read_file,
read_resume_markdown,
apply_diff,
],
llm=llm,
system_prompt=updater_system_prompt,
)
We create the CodingAgent workflow by combinding all these tools, a detailed system_prompt and the llm to use.
Chat Interface
Now let’s create the main chat interface so that it can be used iteratively to get feedback from the user and update the resume.
async def main():
chat_history: List[ChatMessage] = []
while True:
user_msg = input("\n> ")
if user_msg.lower() == "exit":
break
chat_history.append(ChatMessage(role="user", content=user_msg))
handler = RenderResumeWorkflow.run(user_msg=user_msg, chat_history=chat_history)
await log_events(handler, chat_history=chat_history)
await handler
First we initialize an empty chat_history.
Then we enter the main program loop. In each iteration, we check if the user has entered “exit” to break the loop.
If not, we append the user’s message to the chat_history.
Then we run the main RenderResumeWorkflow with the user_msg and the chat_history.
Finally, we log the events and await the handler. In our log_events utility function, we pass the optional chat_history so that the chat history is updated with all the agent and tool output messages.
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter