Better-Resume
A multi-agent resume optimizer using LlamaIndex AgentWorkflow
The goal of this project:
- Create a multi-agent system
- That takes a job posting URL and an existing resume
- Does a thorough analysis of the job posting and the existing resume
- Generates a custom resume tailored specifically for that job posting so that it stands out.
- The optimized resume highlights the skills and experiences that are most relevant to the job posting.
- Render the resume
- Iteratively updates the rendered resume from user’s feedback, including color scheme customization.
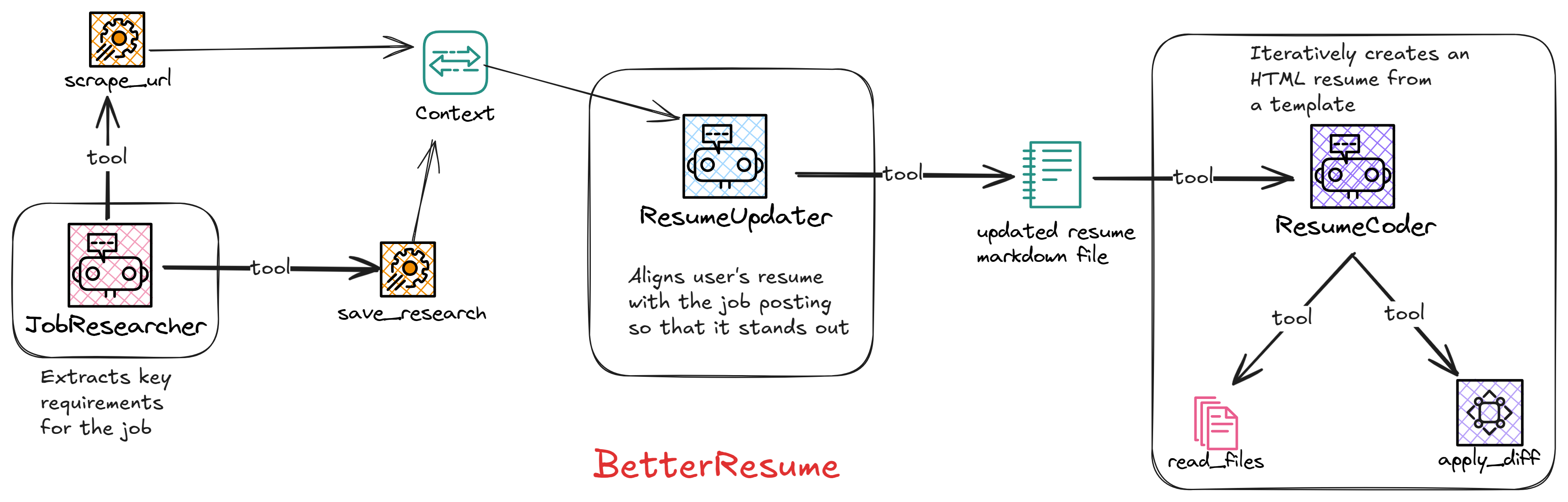
In this first part, we’ll focus on the agents that perform the job research and updated the resume.
In the second part, we’ll see how the coding agent works, that iteratively renders and updates the optimized resume.
Link to the GitHub Repository: Better-Resume
Demo 👇
Resume Updater Workflow
This is our first workflow.
Its responsibility is to take a job posting URL and an existing resume file, and generate a custom resume in markdown, that highlights the skills and qualifications that are most relevant to the job posting.
The generated markdown will be used by other agents later.
from llama_index.core.agent.workflow import AgentWorkflow
from agents import job_research_agent, resume_updater_agent
def get_resume_updater_workflow(url, resume_file):
"""Get the resume updater workflow."""
return AgentWorkflow(
agents=[job_research_agent, resume_updater_agent],
root_agent=job_research_agent.name,
initial_state={
"url": url,
"resume_file": resume_file,
"updated_resume_file_path": "updated_resume.md",
},
)
The reason we’re using a workflow factory function here is that this workflow will be used as a tool in our main workflow, more on this in part 2.
We can see it provides the initial state (job url, resume file, updated resume file) to the workflow context.
It also specifies the root_agent as job_research_agent. This agent will kickoff the workflow and handoff control to other agents as needed.
The agents in this workflow are:
- JobResearcher: For doing analysis on the job.
- ResumeUpdater: For analysing and updating the existing resume.
JobResearcher Agent
llm = Gemini(model="models/gemini-2.0-flash")
job_research_agent = FunctionAgent(
name="JobResearchAgent",
description="Useful for doing amazing analysis on the job posting from the given URL.",
system_prompt=(
"As a skilled job researcher, help pinpoint the necessary "
"qualifications and skills sought by the employer, "
"forming the foundation for effective application tailoring."
"Analyze the job posting URL provided "
"to extract key skills, experiences, and qualifications "
"required. Use the tools to gather content and identify "
"and categorize the requirements. We are expecting the following from you: "
"A structured list of job requirements, including necessary "
"skills, qualifications, and experiences."
),
llm=llm,
tools=[scrape_url, save_research_result],
can_handoff_to=["ResumeUpdaterAgent"],
)
This agent is a FunctionAgent that uses Function calling and requires an LLM that supports it.
We’re using Gemini 2.0 Flash for this.
Other type of Agent is ReactAgent, which works with all LLMs.
In addition to the llm, we provide description and system_prompt to the agent. We specify that this agent can handoff to the ResumeUpdaterAgent once it’s done with its research.
Then we give it the list of tools it has access to.
scrape_url
Scrapes the job posting URL.
async def scrape_url(ctx: Context) -> str:
"""
Useful for getting the contents of a URL and saving them.
"""
current_state = await ctx.get("state")
url = current_state["url"]
print(f"\nGetting contents from url: {url}...\n")
loader = UnstructuredURLLoader(
urls=[url],
continue_on_failure=False,
headers={
"User-Agent": USER_AGENT,
},
)
data = loader.load_data()
current_state["job_posting_data"] = data[0].text
await ctx.set("state", current_state)
return (
f'Contents from the URL "{url}" saved'
if data
else 'Failed to get contents from the URL "{url}"'
)
Here we use UnstructuredURLLoader to scrape the job posting URL and save that to the workflow context.
Next, the agent will use this scraped info do find the key skills, experiences, and qualifications required for the job.
save_research_result
After doing research on the job, the agent uses this tool save the research result to the workflow context, so that other agents can use it later.
async def save_research_result(
ctx: Context,
key_skills: Annotated[List[str], "Key skills required for the job"],
qualifications: Annotated[List[str], "Qualifications required for the job"],
responsibilities: Annotated[List[str], "Main responsibilities of the job"],
experiences: Annotated[List[str], "Experiences required for the job"],
keywords: Annotated[List[str], "Keywords to be used in the resume"],
):
"""
Useful for saving the extracted key skills, responsibilities, experiences
and qualifications required for a job after thoroughly analysing the
jop posting. Use the tools to gather content and identify and categorize
the requirements for a job. This saved info will be used by
other agents later.
"""
current_state = await ctx.get("state")
current_state["job_requirements"] = {
"key_skills": key_skills,
"qualifications": qualifications,
"responsibilities": responsibilities,
"experiences": experiences,
"keywords": keywords,
}
await ctx.set("state", current_state)
return "Job Research result saved successfully."
We can see that we’ve annotated the function parameters with the expected output of the agent, and also gave it a proper docstring. These are very important for the agent to properly extract key requirements.
Finally we have the information to the workflow context for our next Agent, ResumeUpdater
ResumeUpdaterAgent
llm = Gemini(model="models/gemini-2.0-flash")
resume_updater_agent = FunctionAgent(
name="ResumeUpdaterAgent",
description="Useful for finding all the best ways to make a resume stand out in the job market.",
system_prompt=(
"With a strategic mind and an eye for detail, you "
"excel at refining resumes to highlight the most "
"relevant skills and experiences, ensuring they "
"resonate perfectly with the job's requirements."
"Using the existing resume of the user and job requirements obtained "
"before, tailor the resume to highlight the most "
"relevant areas. Employ tools to adjust and enhance the "
"resume content. Make sure this is the best resume ever but "
"don't make up any information. Update every section, "
"inlcuding the initial summary, work experience, skills, "
"and education. All to better reflrect the candidates "
"abilities and how it matches the job posting."
),
llm=llm,
tools=[read_existing_resume, save_updated_resume_content],
)
This is also a FunationAgent and uses Gemini 2.0 Flash
We have given it detailed description and system prompt too. It has access to two tools:
read_existing_resume
async def read_existing_resume(ctx: Context):
"""
Read the existing resume from the context.
"""
current_state = await ctx.get("state")
try:
resume_file = current_state.get("resume_file")
print(f"\nReading resume contents from {resume_file}...\n")
docs = SimpleDirectoryReader(
input_files=[resume_file],
).load_data()
current_state["resume"] = docs[0].text
await ctx.set("state", current_state)
return "Resume read successfully."
except FileNotFoundError:
return "Resume file not found."
It uses SimpleDirectoryReader from LLamaIndex to read the existing resume file and save it to the workflow context.
Next, it uses the job research result from the context and this existing resume to do thorough analysis.
It comes up with a strategy to update the existing resume based on the job research so that it stands out. And once that’s done, its time to save the new resume as markdown.
save_updated_resume_content
async def save_updated_resume_content(
ctx: Context,
updated_resume_in_markdown: Annotated[
str,
"Full updated resume in markdown format with all the sections like Full name of the candidate, headline, summary, experiences, projects, skills, contact info extracted from previous resume like email, phone number, website, github, linkedin url etc. The headline must reflect the job title and include relevant keywords from the job posting. The summary must be tailored to highlight the most relevant skills, experience, and achievements that match the job posting. The summary must be under 35 words. The experiences and projects must be rewritten to emphasize achievements and responsibilities that align with the job requirements. Extract all information for experiences and projects like start end year, job title, workplace etc. The description of the experiences and projects must be Rewritten list of bullet points to emphasize achievements and responsibilities of this experience that align with the job requirements. The skills must be grouped by relevant and similar skills, sorted by relevance and importance to the job.",
] = "",
) -> str:
"""
Useful for saving the updated resume content after thoroughly analyzing
the job requirements and the user's previous resume. This updated resume
is tailored to highlight the most relevant skills, experience,
and achievements that match the job posting. The info saved by this tool
will be used by other agents later to create the final updated resume.
"""
current_state = await ctx.get("state")
current_state["resume_content"] = updated_resume_in_markdown
updated_resume_file_path = current_state.get("updated_resume_file_path")
with open(updated_resume_file_path, "w") as f:
f.write(updated_resume_in_markdown)
await ctx.set("state", current_state)
return "Job Research result saved successfully."
Again, we use very detailed docstring and annotations so that the agent knows exactly what to do with this tool.
Finally, it saves the updated resume content to a markdown file. We can edit the generated markdown (updated_resume.md) to our liking.
In the next part, we’ll see how the CodingAgent takes this markdown and an html template to iteratively code and update the resume.
Thanks for reading. Stay tuned for more.
I tweet about these topics and anything I’m exploring on a regular basis. Follow me on twitter